CUDA Matrix Multiply: From Naive Baseline to Near-cuBLAS Performance
Introduction
General Matrix Multiply (GEMM) computes C = αAB + βC and is the computational backbone of deep learning. Every linear layer, attention mechanism, and convolution (via im2col) reduces to GEMM. Understanding how to optimize it reveals the core principles of GPU performance.
This post implements single-precision GEMM (SGEMM) from scratch using CUDA cores only, no tensor cores. We progressively optimize from a naive baseline to 89% of cuBLAS performance on an H200. A follow-up post will explore tensor core acceleration. The benchmark code is available in this repository.
The Problem
Given matrices A ($M \times K$) and B ($K \times N$), compute C ($M \times N$) where each element is a dot product:
\[c_{ij} = \sum_{k=0}^{K-1} a_{ik} \cdot b_{kj}\]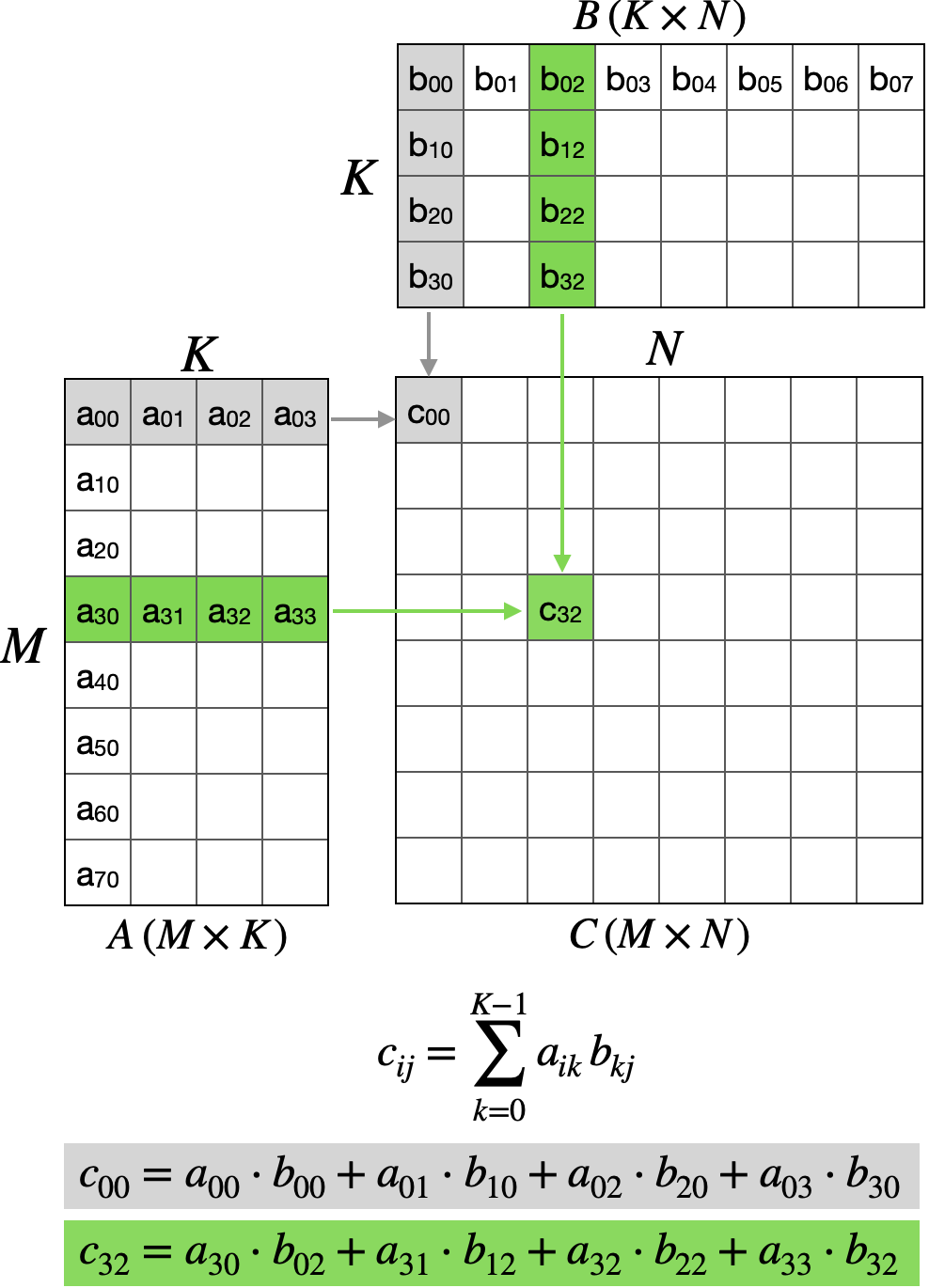
The naive approach assigns one thread per output element. Each thread independently computes a dot product by iterating through the K dimension. This results in massive redundant global memory traffic: every row of A and column of B is re-read N and M times respectively.
Kernel 1: Naive Baseline
template <int BM, int BN>
__global__ void sgemm_baseline(
int M, int N, int K, float alpha,
const float *A, const float *B, float beta, float *C)
{
// 1D thread index
uint tid = threadIdx.x;
// Convert 1D thread index to 2D position within a block tile
uint tx = tid % BN; // column within block
uint ty = tid / BN; // row within block
// Global position in C
uint col = blockIdx.x * BN + tx;
uint row = blockIdx.y * BM + ty;
if (row < M && col < N) {
// Compute dot product
float sum = 0.0f;
for (uint k = 0; k < K; ++k) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = alpha * sum + beta * C[row * N + col];
}
}
// Host side kernel launch
dim3 grid((N + BN - 1) / BN, (M + BM - 1) / BM);
dim3 block(BM * BN);
sgemm_baseline<BM, BN><<<grid, block>>>(M, N, K, alpha, A, B, beta, C);
Each thread loads K elements from A and K elements from B. That’s 2K floats = 8K bytes. For those loads, we get K multiply-adds = 2K FLOPs. The arithmetic intensity:
\[\text{Arithmetic Intensity} = \frac{2K \text{ FLOPs}}{8K \text{ bytes}} = 0.25 \text{ FLOPs/byte}\]Modern GPUs need 10-30+ FLOPs/byte to be compute-bound. At 0.25, we’re severely memory-bound with zero data reuse.
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 01_Baseline | 269.5 | 4.1 | 8% |
Kernel 2: Block Tiling with Shared Memory
The insight: threads within a block can share data. By loading tiles of A and B into shared memory cooperatively, we amortize global memory traffic across all threads in the block.
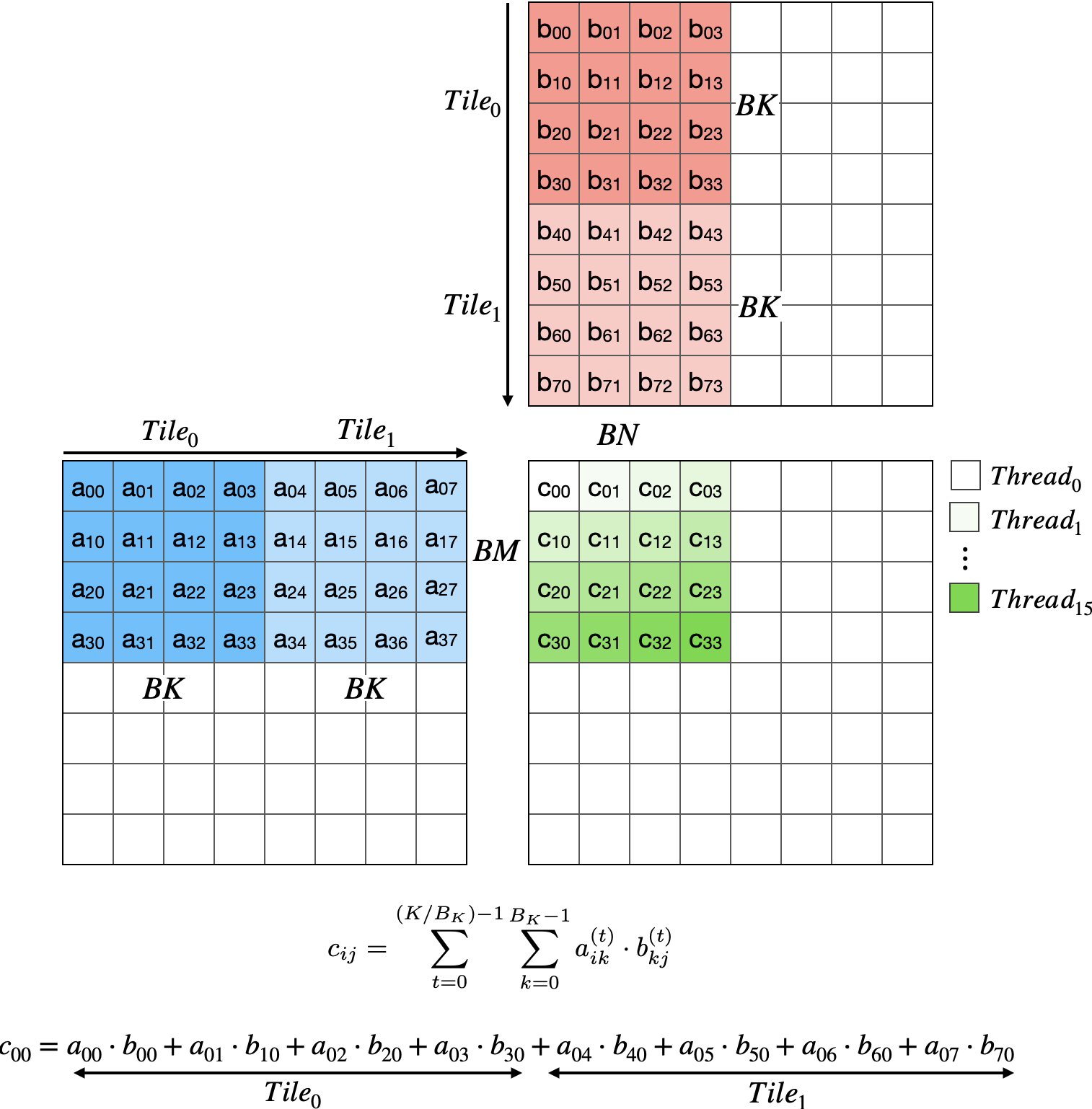
This reduces global memory reads from 2K per thread to 2K/BK per thread for the cooperative loads. With BK=32, that’s a $32\times$ reduction in global traffic.
However, we’re still limited: each thread computes one output (2K FLOPs) while the block loads $(BM \times BK + BK \times BN)$ floats per tile $\times$ K/BK tiles. The arithmetic intensity improves but remains modest because each thread only produces one output.
template <int BM, int BN, int BK>
__global__ void sgemm_block_tiling(
int M, int N, int K, float alpha,
const float *A, const float *B, float beta, float *C)
{
static_assert(BK == BN && BK == BM, "This kernel requires BM == BN == BK");
__shared__ float As[BM * BK];
__shared__ float Bs[BK * BN];
// 1D thread index
uint tid = threadIdx.x;
// Convert to 2D position within block tile
uint tx = tid % BN; // column within block
uint ty = tid / BN; // row within block
// Global position in C
uint col = blockIdx.x * BN + tx;
uint row = blockIdx.y * BM + ty;
// Move A and B pointers to this block's starting position
A += blockIdx.y * BM * K;
B += blockIdx.x * BN;
float sum = 0.0f;
// Loop over tiles along K
for (uint tileIdx = 0; tileIdx < K; tileIdx += BK) {
// Load tile into shared memory
// Each thread loads one element of As and one element of Bs
As[ty * BK + tx] = A[ty * K + tx]; // Note: tx < BK required
Bs[ty * BN + tx] = B[ty * N + tx]; // Note: ty < BK required
__syncthreads();
// Advance pointers for next iteration
A += BK;
B += BK * N;
// Compute partial dot product from shared memory
for (uint k = 0; k < BK; ++k) {
sum += As[ty * BK + k] * Bs[k * BN + tx];
}
__syncthreads();
}
if (row < M && col < N) {
C[row * N + col] = alpha * sum + beta * C[row * N + col];
}
}
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 01_Baseline | 269.5 | 4.1 | 8% |
| 02_BlockTiling | 123.2 | 8.9 | 17% |
Kernel 3: Thread Tiling (2D Register Blocking)
Block tiling reduces global memory traffic, but each thread still makes BK trips to shared memory per inner loop. The next insight: have each thread compute a tile of outputs, not just one element.
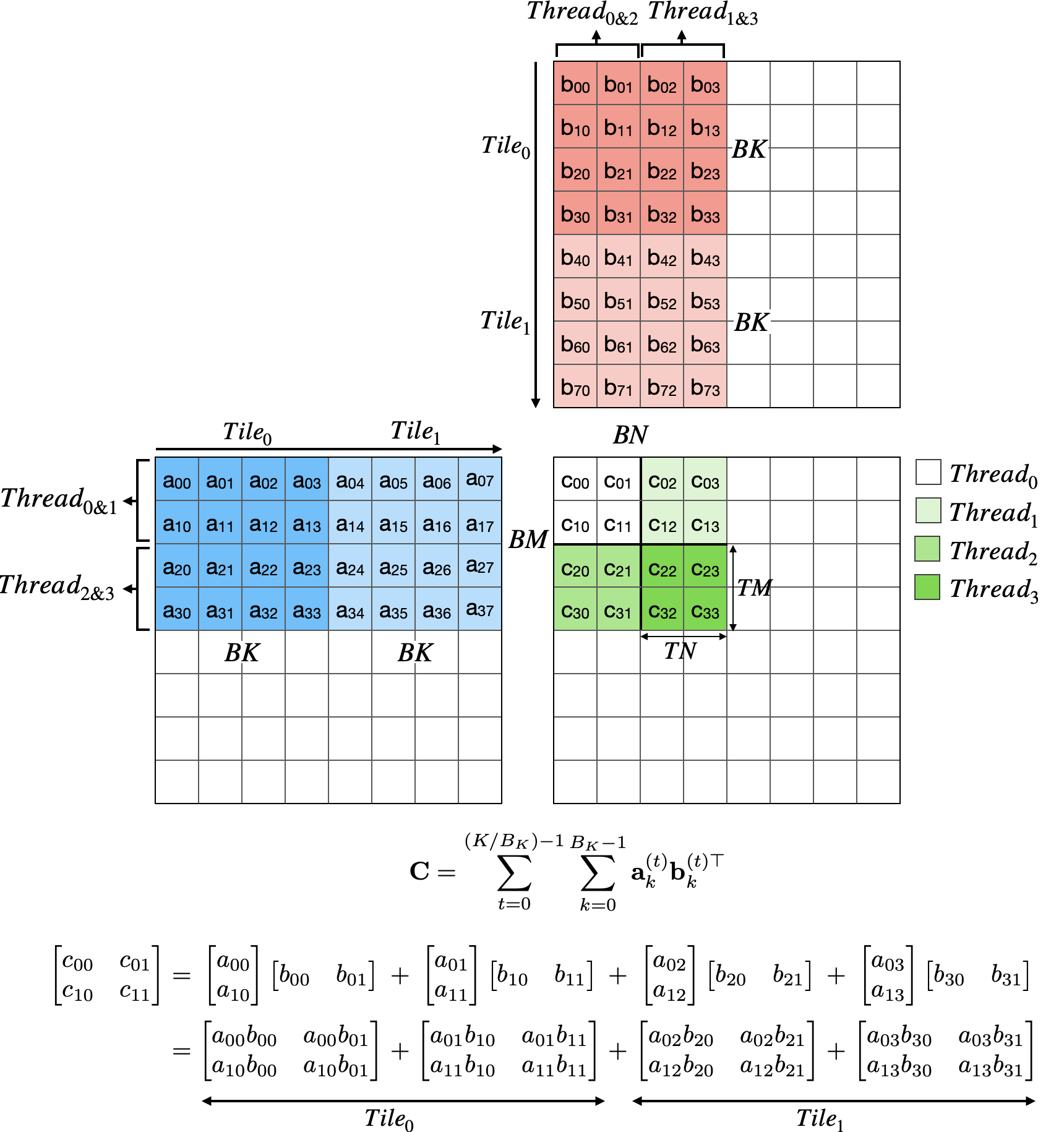
Instead of dot products, we compute outer products. Each thread loads TM values from A and TN values from B into registers, then computes all $TM \times TN$ products. This amortizes the shared memory loads across $TM \times TN$ outputs.
template <int BM, int BN, int BK, int TM, int TN>
__global__ void sgemm_thread_tiling(
int M, int N, int K, float alpha,
const float *A, const float *B, float beta, float *C)
{
constexpr int NUM_THREADS = (BM / TM) * (BN / TN);
__shared__ float As[BM * BK];
__shared__ float Bs[BK * BN];
uint tid = threadIdx.x;
// Thread position in block
uint tx = tid % (BN / TN);
uint ty = tid / (BN / TN);
// Global starting position for this thread's tile
uint colStart = blockIdx.x * BN + tx * TN;
uint rowStart = blockIdx.y * BM + ty * TM;
// Move A and B pointers to this block's starting position
A += blockIdx.y * BM * K;
B += blockIdx.x * BN;
// Registers for results and fragments
float tmp[TM * TN] = {0.0f};
float regM[TM];
float regN[TN];
// How many elements each thread loads
constexpr uint numAPerThread = (BM * BK) / NUM_THREADS;
constexpr uint numBPerThread = (BK * BN) / NUM_THREADS;
// Loop over tiles along K
for (uint tileIdx = 0; tileIdx < K; tileIdx += BK) {
// Load As into shared memory
for (uint i = 0; i < numAPerThread; ++i) {
uint idx = tid + i * NUM_THREADS;
uint aRow = idx / BK;
uint aCol = idx % BK;
As[aRow * BK + aCol] = A[aRow * K + aCol];
}
// Load Bs into shared memory
for (uint i = 0; i < numBPerThread; ++i) {
uint idx = tid + i * NUM_THREADS;
uint bRow = idx / BN;
uint bCol = idx % BN;
Bs[bRow * BN + bCol] = B[bRow * N + bCol];
}
__syncthreads();
A += BK;
B += BK * N;
// Compute outer products
for (uint k = 0; k < BK; ++k) {
// Load regM from As
for (uint m = 0; m < TM; ++m) {
regM[m] = As[(ty * TM + m) * BK + k];
}
// Load regN from Bs
for (uint n = 0; n < TN; ++n) {
regN[n] = Bs[k * BN + tx * TN + n];
}
// Outer product
for (uint m = 0; m < TM; ++m) {
for (uint n = 0; n < TN; ++n) {
tmp[m * TN + n] += regM[m] * regN[n];
}
}
}
__syncthreads();
}
// Write results
for (uint m = 0; m < TM; ++m) {
uint row = rowStart + m;
for (uint n = 0; n < TN; ++n) {
uint col = colStart + n;
if (row < M && col < N) {
C[row * N + col] = alpha * tmp[m * TN + n] + beta * C[row * N + col];
}
}
}
}
With TM=TN=8, each thread computes 64 outputs. Per K iteration, a thread loads TM + TN = 16 values from shared memory and performs $TM \times TN$ = 64 multiply-adds = 128 FLOPs. The arithmetic intensity for shared memory access:
\[\frac{128 \text{ FLOPs}}{16 \times 4 \text{ bytes}} = 2.0 \text{ FLOPs/byte}\]That’s $8\times$ better than the naive kernel. The global memory intensity improves even more dramatically since shared memory loads are amortized across all BK iterations.
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 01_Baseline | 269.5 | 4.1 | 8% |
| 02_BlockTiling | 123.2 | 8.9 | 17% |
| 03_ThreadTiling | 59.0 | 18.6 | 36% |
Kernel 4: Vectorized Memory Access
Global memory transactions are most efficient at 128 bits (float4). We apply vectorization to both global→shared loads and shared→register loads.
Loading A (with transpose):
Matrix A is row-major, but threads reading a column of As for their regM fragment would cause strided access. We transpose during the store:
// Load 4 floats from a row of A
float4 tmp4 = reinterpret_cast<const float4*>(&A[aRow * K + aCol])[0];
// Store transposed: row becomes column
As[(aCol + 0) * BM + aRow] = tmp4.x;
As[(aCol + 1) * BM + aRow] = tmp4.y;
As[(aCol + 2) * BM + aRow] = tmp4.z;
As[(aCol + 3) * BM + aRow] = tmp4.w;
Now reading a column of As (for regM) accesses consecutive addresses.
Loading B (contiguous):
Matrix B loads directly. Rows of B map to rows of Bs, and threads reading regN access consecutive elements:
// Load 4 floats from B
float4 tmp4 = reinterpret_cast<const float4*>(&B[bRow * N + bCol])[0];
// Store directly (no transpose needed)
reinterpret_cast<float4*>(&Bs[bRow * BN + bCol])[0] = tmp4;
Vectorized fragment loads:
The same principle applies when loading from shared memory to registers. With TM=8, we load regM as two float4 operations:
for (uint m = 0; m < TM; m += 4) {
float4 tmp4 = reinterpret_cast<const float4*>(&As[k * BM + ty * TM + m])[0];
regM[m + 0] = tmp4.x;
regM[m + 1] = tmp4.y;
regM[m + 2] = tmp4.z;
regM[m + 3] = tmp4.w;
}
The same pattern applies to regN. Both kernels 04a (vectorized global only) and 04b (vectorized global + shared) were benchmarked:
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 03_ThreadTiling | 59.0 | 18.6 | 36% |
| 04a_VecGmem | 33.9 | 32.5 | 63% |
| 04b_VecGmemSmem | 32.4 | 33.9 | 66% |
Kernel 5: Double Buffering
So far, each tile iteration follows: load → sync → compute → sync. The compute phase sits idle while waiting for loads. Double buffering overlaps load of tile i+1 with computation on tile i.
The pipeline pattern:
Without double buffering:
[Load 0][Sync][Compute 0][Sync][Load 1][Sync][Compute 1][Sync]...
With double buffering:
[Load 0][Sync]
[Compute 0 + Load 1][Sync]
[Compute 1 + Load 2][Sync]...
The kernel follows a prologue → main loop → epilogue structure:
__shared__ float As[2][BK * BM]; // Two buffers
__shared__ float Bs[2][BK * BN];
// ====== PROLOGUE ======
// Load first tile (no overlap possible yet)
loadTileA(A, As[0], ...);
loadTileB(B, Bs[0], ...);
__syncthreads();
A += BK;
B += BK * N;
// Prefetch first fragment to registers
loadFragment(As[0], Bs[0], regM[0], regN[0], 0, ...);
// ====== MAIN LOOP ======
uint smemWrite = 1, smemRead = 0;
for (uint tile = 1; tile < numTiles; ++tile) {
// Prefetch next tile to alternate buffer
loadTileA(A, As[smemWrite], ...);
loadTileB(B, Bs[smemWrite], ...);
A += BK;
B += BK * N;
// Process current tile (overlapped with loads)
processTile(As[smemRead], Bs[smemRead], regM, regN, tmp, ...);
__syncthreads();
// Swap buffers
smemWrite = 1 - smemWrite;
smemRead = 1 - smemRead;
// Prefetch first fragment of next tile
loadFragment(As[smemRead], Bs[smemRead], regM[0], regN[0], 0, ...);
}
// ====== EPILOGUE ======
// Process final tile (no more loads)
processTile(As[smemRead], Bs[smemRead], regM, regN, tmp, ...);
// Write results to global memory
storeResult(C, tmp, ...);
We also double-buffer at the register level: while computing with regM[0]/regN[0], prefetch regM[1]/regN[1] for the next k iteration. Both shared memory (05a) and register (05b) double buffering were benchmarked:
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 04b_VecGmemSmem | 32.4 | 33.9 | 66% |
| 05a_DoubleBufferSmem | 26.6 | 41.3 | 81% |
| 05b_DoubleBufferSmemReg | 26.5 | 41.5 | 81% |
Kernel 6: Asynchronous Copy (Ampere+)
On SM80+, cp.async copies data directly from global to shared memory without staging through registers:
__pipeline_memcpy_async(
&Bs[bRow * BN + bCol],
&B[bRow * N + bCol],
sizeof(float4)
);
__pipeline_commit();
// ... compute while copy is in flight ...
__pipeline_wait_prior(0);
__syncthreads();
This further improves latency hiding by freeing registers that would otherwise hold in-flight data.
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| 05b_DoubleBufferSmemReg | 26.5 | 41.5 | 81% |
| 06_AsyncCopy | 25.7 | 42.8 | 83% |
Autotuning
Template parameters (BM, BN, BK, TM, TN) significantly impact performance. Rather than guess, we autotune across configurations:
[Autotune] Testing 20 configurations on 8192x8192x8192...
64x64x16_8x8 28.175 ms 39.02 TFLOPS
64x128x16_8x8 24.842 ms 44.26 TFLOPS
64x256x16_8x8 24.224 ms 45.39 TFLOPS <- Best
128x128x16_8x8 25.675 ms 42.82 TFLOPS
...
[Autotune] Best: 64x256x16_8x8 (24.224 ms, 45.39 TFLOPS)
The optimal configuration ($64 \times 256 \times 16$ with $8 \times 8$ thread tiles) differs from CUTLASS defaults because our implementation uses row-major layouts and different memory access patterns.
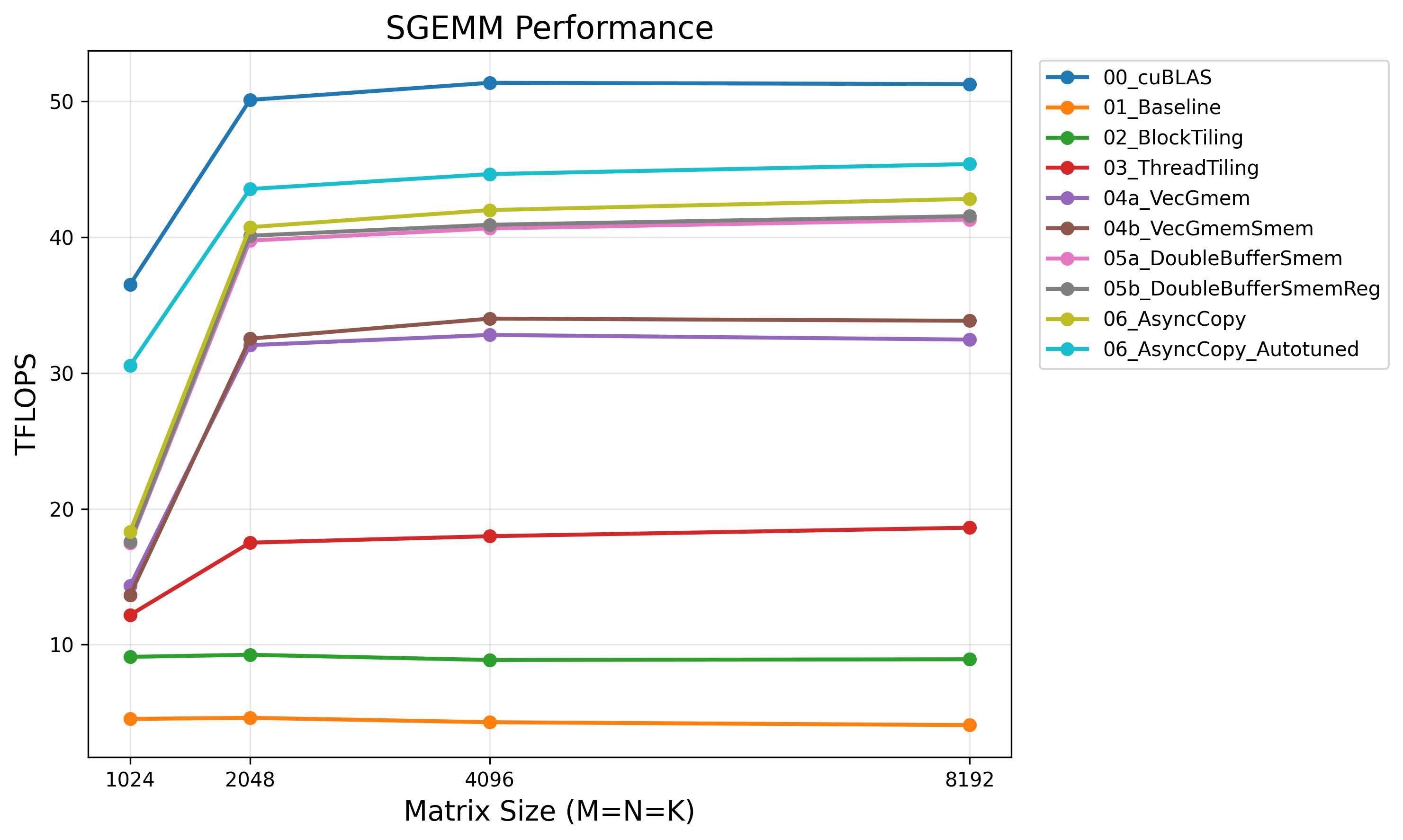
Results
Benchmarked on NVIDIA H200 (141 GB HBM3e) with N=8192:
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| cuBLAS (FP32) | 21.4 | 51.3 | 100% |
| 01_Baseline | 269.5 | 4.1 | 8% |
| 02_BlockTiling | 123.2 | 8.9 | 17% |
| 03_ThreadTiling | 59.0 | 18.6 | 36% |
| 04a_VecGmem | 33.9 | 32.5 | 63% |
| 04b_VecGmemSmem | 32.4 | 33.9 | 66% |
| 05a_DoubleBufferSmem | 26.6 | 41.3 | 81% |
| 05b_DoubleBufferSmemReg | 26.5 | 41.5 | 81% |
| 06_AsyncCopy | 25.7 | 42.8 | 83% |
| 06_AsyncCopy_Autotuned | 24.2 | 45.4 | 89% |
The Gap to cuBLAS
The remaining 11% gap comes from techniques we haven’t implemented:
- Shared memory swizzling: XOR-based addressing to eliminate bank conflicts entirely
- Warp specialization: Dedicated producer/consumer warps for better pipelining
- Instruction scheduling: Hand-tuned assembly for optimal ILP
- Tensor cores: cuBLAS uses TF32 by default for FP32 inputs (we disabled this for fair comparison via
CUBLAS_COMPUTE_32F)
For a hand-written SIMT kernel, 89% of cuBLAS is a reasonable ceiling without diving into PTX.
Conclusion
GEMM optimization follows a clear hierarchy:
- Reduce global memory traffic: Block tiling with shared memory
- Increase arithmetic intensity: Thread tiling (outer products)
- Maximize memory bandwidth: Vectorized loads, coalesced access
- Hide latency: Double buffering, async copy
- Find optimal parameters: Autotuning
The same principles (tiling, vectorization, latency hiding) recur throughout GPU optimization. Master them on GEMM and they transfer everywhere.
References
- CUDA Matrix Multiplication by Simon Boehm
- Advanced Matrix Multiplication Optimization on NVIDIA GPUs by Aman Salykov