Tensor Core HGEMM: Dropping to PTX mma.sync
Introduction
The previous post used the WMMA API to reach 80% of cuBLAS on A100. WMMA is convenient—fragments are opaque, loads are automatic—but that abstraction costs performance. The compiler chooses the fragment layout, the load strategy, and the shared memory access pattern. We can do better.
This post drops to PTX mma.sync and ldmatrix instructions, giving us direct control over fragment register layout, shared memory access patterns, and instruction scheduling. Starting from the same block tiling structure as the WMMA series, we progress from an educational element-by-element baseline to 88% of cuBLAS on A100. The benchmark code is available in this repository.
The focus here is on what changes when you move from WMMA to PTX: the m16n8k16 tile shape, the non-opaque fragment layouts, and the two strategies for loading fragments from shared memory (direct vs. ldmatrix). Optimizations that carry over unchanged from WMMA—async copy, multi-stage pipelining, software pipelining, block swizzle—are covered briefly. See the WMMA post for the full treatment of those.
Why Drop to PTX?
WMMA operates on 16×16×16 tiles and hides the fragment layout. This simplicity comes with three costs:
No swizzle compatibility. WMMA’s load_matrix_sync accesses shared memory through an opaque pattern that we can’t align with XOR swizzle. In the WMMA series, the best we could do was pad shared memory rows by 8 elements—a 25% overhead on a BK=32 tile. With PTX, we control the exact address each lane feeds to ldmatrix, so we can apply swizzle directly.
No ldmatrix access. The ldmatrix instruction is a warp-collective load that moves an entire 8×8 matrix tile from shared memory to registers in a single transaction, with automatic cross-lane data shuffling. WMMA may or may not use it under the hood—we can’t tell, and we can’t control it.
Coarser scheduling granularity. WMMA’s 16×16×16 tile produces a 16×16 output. PTX mma.sync.m16n8k16 produces a 16×8 output—half the N dimension. This finer granularity gives the compiler more flexibility to interleave loads with computation.
The m16n8k16 Instruction
The PTX instruction we’ll use throughout this post is:
mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16
Breaking down each qualifier:
mma: Matrix Multiply-Accumulate. Computes D = A × B + C..sync: All threads in the warp must reach this instruction before any thread proceeds. Acts as an implicit warp barrier..aligned: All threads in the warp must execute the same instruction (no divergence allowed). Required for warp-level matrix operations..m16n8k16: Tile dimensions — A is 16×16 (M×K), B is 16×8 (K×N), C/D are 16×8 (M×N)..row: Matrix A is in row-major layout..col: Matrix B is in column-major layout. This asymmetry is a hardware constraint —mma.syncalways expects A row-major and B column-major..f16.f16.f16.f16: Data types for D, A, B, C respectively. All four are FP16 in our case. Other combinations exist (e.g.,.f32.f16.f16.f32for FP32 accumulation).
The inline PTX wrapper:
__device__ __forceinline__
void mma_sync(FragmentC& acc,
const FragmentA& A,
const FragmentB& B) {
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 "
"{%0,%1}, {%2,%3,%4,%5}, {%6,%7}, {%0,%1};\n"
: "+r"(acc.reg[0]), "+r"(acc.reg[1])
: "r"(A.reg[0]), "r"(A.reg[1]), "r"(A.reg[2]), "r"(A.reg[3]),
"r"(B.reg[0]), "r"(B.reg[1])
);
}
Fragment A requires 4 registers (8 FP16 values), fragment B requires 2 registers (4 FP16 values), and fragment C/D requires 2 registers (4 FP16 values). This register layout is not opaque—it’s fully specified in the PTX ISA documentation, and understanding it is the key to everything that follows.
Fragment Layouts: The Register-to-Matrix Mapping
With WMMA, fragments are opaque—you call load_matrix_sync and trust the API. With PTX, we must understand exactly which matrix element each thread holds in each register. This mapping determines how we load data from shared memory.
Each register holds a uint32_t packing two FP16 values. We can index into the 8 elements of an A fragment (or 4 elements of B/C) and ask: for thread lane holding element i, which (row, col) of the matrix does it correspond to?
Fragment A (16×16, row-major, 8 elements per thread):
The 32 threads in a warp are organized into 8 groups of 4. The group ID (lane >> 2) selects the row within a half-tile, and the position within the group (lane & 3) selects a column pair. The 8 elements span two row-halves (0–7 and 8–15) and two column-halves (0–7 and 8–15):
struct FragmentA {
uint32_t reg[4]; // 4 registers × 2 halves = 8 elements
static __device__ int get_row(int lane, int i) {
int group_id = lane >> 2;
return group_id + 8 * ((i >> 1) & 1);
}
static __device__ int get_col(int lane, int i) {
int tid_in_group = lane & 3;
return tid_in_group * 2 + (i & 1) + 8 * (i >> 2);
}
};

Let’s trace thread 0 (lane=0, group_id=0, tid_in_group=0):
THREAD 0 (lane=0) OWNS THESE 8 ELEMENTS OF THE 16×16 A MATRIX
═══════════════════════════════════════════════════════════════
i=0: row = 0 + 8*0 = 0, col = 0*2 + 0 + 8*0 = 0 → A[0][0]
i=1: row = 0 + 8*0 = 0, col = 0*2 + 1 + 8*0 = 1 → A[0][1]
i=2: row = 0 + 8*1 = 8, col = 0*2 + 0 + 8*0 = 0 → A[8][0]
i=3: row = 0 + 8*1 = 8, col = 0*2 + 1 + 8*0 = 1 → A[8][1]
i=4: row = 0 + 8*0 = 0, col = 0*2 + 0 + 8*1 = 8 → A[0][8]
i=5: row = 0 + 8*0 = 0, col = 0*2 + 1 + 8*1 = 9 → A[0][9]
i=6: row = 0 + 8*1 = 8, col = 0*2 + 0 + 8*1 = 8 → A[8][8]
i=7: row = 0 + 8*1 = 8, col = 0*2 + 1 + 8*1 = 9 → A[8][9]
Registers:
reg[0] = {A[0][0], A[0][1]} ← elements i=0,1 (row 0, cols 0-1)
reg[1] = {A[8][0], A[8][1]} ← elements i=2,3 (row 8, cols 0-1)
reg[2] = {A[0][8], A[0][9]} ← elements i=4,5 (row 0, cols 8-9)
reg[3] = {A[8][8], A[8][9]} ← elements i=6,7 (row 8, cols 8-9)
The pattern: registers 0–1 cover the left half (columns 0–7) and registers 2–3 cover the right half (columns 8–15). Within each half, even registers hold the top half (rows 0–7) and odd registers hold the bottom half (rows 8–15). This 2×2 structure over the four 8×8 quadrants of the 16×16 matrix will become important when we look at ldmatrix.
Fragment B (16×8, column-major input, 4 elements per thread):
Fragment B has a different layout because mma.sync expects B in column-major order (.col in the instruction encoding). B is 16 rows (K dimension) by 8 columns (N dimension), and each thread holds 4 elements:
struct FragmentB {
uint32_t reg[2]; // 2 registers × 2 halves = 4 elements
static __device__ int get_row(int lane, int i) {
return (lane & 3) * 2 + (i & 1) + 8 * (i >> 1);
}
static __device__ int get_col(int lane, int i) {
return lane >> 2;
}
};
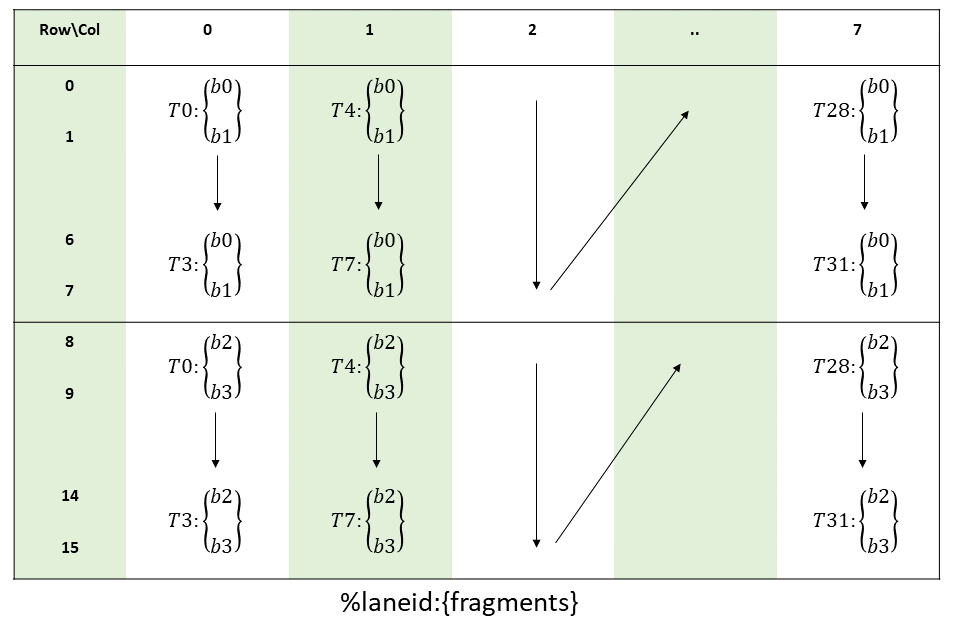
A key implication: all 4 threads within a group share the same column. Thread 0 (lane=0) owns column 0, thread 4 (lane=4) owns column 1, and so on. The group ID directly maps to the column index—this is the column-major layout that .col requires.
Let’s trace thread 0 (lane=0, tid_in_group = lane & 3 = 0, group_id = lane >> 2 = 0):
THREAD 0 (lane=0) OWNS THESE 4 ELEMENTS OF THE 16×8 B MATRIX
═══════════════════════════════════════════════════════════════
i=0: row = 0*2 + 0 + 8*0 = 0, col = 0 >> 2 = 0 → B[0][0]
i=1: row = 0*2 + 1 + 8*0 = 1, col = 0 >> 2 = 0 → B[1][0]
i=2: row = 0*2 + 0 + 8*1 = 8, col = 0 >> 2 = 0 → B[8][0]
i=3: row = 0*2 + 1 + 8*1 = 9, col = 0 >> 2 = 0 → B[9][0]
Registers:
reg[0] = {B[0][0], B[1][0]} ← elements i=0,1 (rows 0-1, col 0)
reg[1] = {B[8][0], B[9][0]} ← elements i=2,3 (rows 8-9, col 0)
The pattern: register 0 holds two consecutive rows from the top half (rows 0–7), register 1 holds two consecutive rows from the bottom half (rows 8–15). All elements in a single thread belong to the same column. This is a column-major view of the matrix, packed vertically within each register.
Fragment C/D (16×8, 4 elements per thread):
struct FragmentC {
uint32_t reg[2];
static __device__ int get_row(int lane, int i) {
return (lane >> 2) + 8 * (i >> 1);
}
static __device__ int get_col(int lane, int i) {
return (lane & 3) * 2 + (i & 1);
}
};
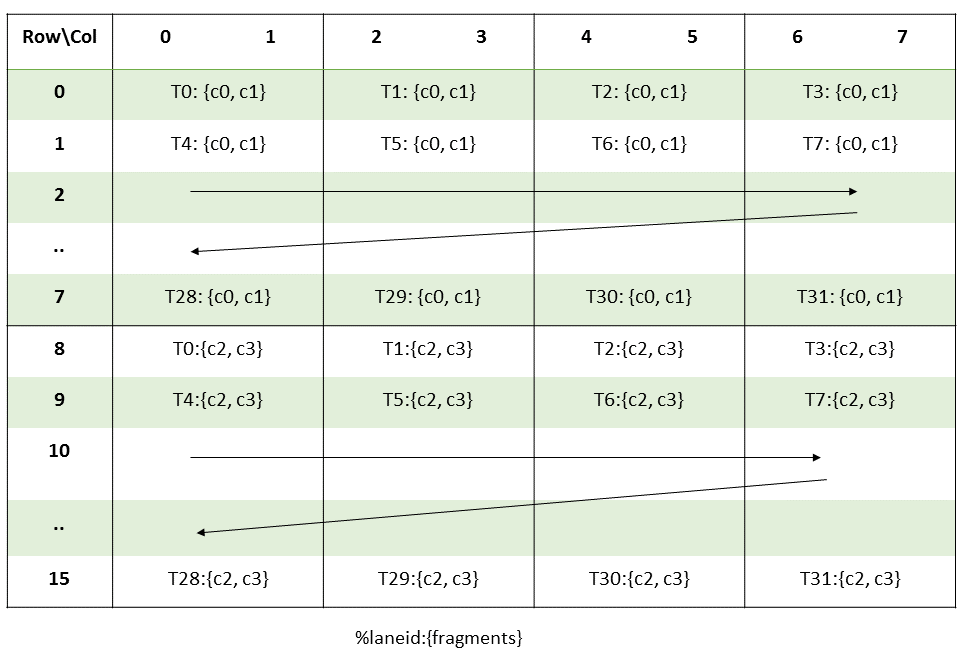
The C fragment uses the same grouping as A for rows (group_id = lane >> 2 selects the row) and the same pairing as both A and B for columns (consecutive elements in the same register form a column pair).
Let’s trace thread 0 (lane=0, group_id = lane >> 2 = 0, tid_in_group = lane & 3 = 0):
THREAD 0 (lane=0) OWNS THESE 4 ELEMENTS OF THE 16×8 C MATRIX
═══════════════════════════════════════════════════════════════
i=0: row = 0 + 8*0 = 0, col = 0*2 + 0 = 0 → C[0][0]
i=1: row = 0 + 8*0 = 0, col = 0*2 + 1 = 1 → C[0][1]
i=2: row = 0 + 8*1 = 8, col = 0*2 + 0 = 0 → C[8][0]
i=3: row = 0 + 8*1 = 8, col = 0*2 + 1 = 1 → C[8][1]
Registers:
reg[0] = {C[0][0], C[0][1]} ← elements i=0,1 (row 0, cols 0-1)
reg[1] = {C[8][0], C[8][1]} ← elements i=2,3 (row 8, cols 0-1)
The pattern: register 0 holds a consecutive column pair from the top half (rows 0–7), register 1 holds the same column pair from the bottom half (rows 8–15). This is the same row-major packing as fragment A, but over a 16×8 tile instead of 16×16.
Kernel 01a: Direct Fragment Loads
With the fragment layout understood, the simplest loading strategy is element-by-element: each thread computes its (row, col) for every element and reads directly from shared memory.
template<int STRIDE>
__device__ __forceinline__
void load_fragment_direct(FragmentA& frag, const __half* smem_ptr) {
int lane = threadIdx.x & 31;
__half* elements = reinterpret_cast<__half*>(frag.reg);
#pragma unroll
for (int i = 0; i < 8; ++i) {
int row = FragmentA::get_row(lane, i);
int col = FragmentA::get_col(lane, i);
elements[i] = smem_ptr[row * STRIDE + col];
}
}
This generates 8 individual 2-byte loads per thread for fragment A (4 for B). It’s correct and educational, but the memory system strongly prefers larger transactions.
The kernel structure is identical to the WMMA baseline, except fragments are our explicit structs instead of wmma::fragment, and the MMA call is inline PTX instead of wmma::mma_sync. Global-to-shared loading uses cp.async with float4 vectorization, same as in the WMMA post.
for (int tileK = 0; tileK < K; tileK += BK) {
// Global -> Shared (cp.async, float4)
loadTileA_async<BM, BK, NUM_THREADS>(A, As, K, tid);
loadTileB_async<BK, BN, NUM_THREADS>(B, Bs, N, tid);
cp_async_commit();
cp_async_wait<0>();
__syncthreads();
for (int innerK = 0; innerK < BK; innerK += MMA_K) {
FragmentA a_frag[MMA_M_TILES];
for (int m = 0; m < MMA_M_TILES; ++m)
load_fragment_direct<BK>(a_frag[m],
&As[(warpM * WM + m * MMA_M) * BK + innerK]);
FragmentB b_frag[MMA_N_TILES];
for (int n = 0; n < MMA_N_TILES; ++n)
load_fragment_direct<BN>(b_frag[n],
&Bs[innerK * BN + warpN * WN + n * MMA_N]);
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
mma_sync(acc[m][n], a_frag[m], b_frag[n]);
}
__syncthreads();
}
Note the tile shape difference from WMMA: each MMA tile is now 16×8 in the N dimension (MMA_N=8), so with WN=64 we need MMA_N_TILES = 64/8 = 8 B fragments per warp, compared to 4 with WMMA’s 16×16 tiles. We issue twice as many MMA instructions for the same work, but each instruction is cheaper.
Performance: 75 TFLOPS at N=8192 (26% of cuBLAS)
Kernel 01b: ldmatrix — The Hardware Solution
The direct load approach has an obvious problem: 8 individual 2-byte shared memory reads per thread for a single A fragment. That’s 8 × 32 = 256 separate transactions per warp for what is fundamentally a structured 16×16 tile load. The hardware has a better way.
ldmatrix is a warp-collective PTX instruction that loads one or more 8×8 matrix tiles from shared memory into registers. Each lane provides an address pointing to one row of an 8×8 tile (8 halves = 16 bytes), and the hardware redistributes the data across lanes so that every thread ends up with the register values that mma.sync expects. The entire operation completes in a single transaction.
Loading Fragment A with ldmatrix.x4:
A 16×16 fragment decomposes into four 8×8 tiles. We use ldmatrix.sync.aligned.m8n8.x4 to load all four at once. The 32 warp lanes are partitioned into 4 groups of 8, each responsible for one tile:
16×16 A FRAGMENT → FOUR 8×8 TILES
══════════════════════════════════════════════════════
columns 0-7 columns 8-15
┌──────────────┬──────────────┐
rows │ tile 0 │ tile 2 │
0-7 │ lanes 0-7 │ lanes 16-23 │
├──────────────┼──────────────┤
rows │ tile 1 │ tile 3 │
8-15 │ lanes 8-15 │ lanes 24-31 │
└──────────────┴──────────────┘
Lane → tile assignment: tile_id = lane >> 3
Lane → row within tile: row_in_tile = lane & 7
Each lane provides an address to row (row_in_tile) of its tile.
Hardware loads 16 bytes per lane and shuffles into correct registers.
template<int STRIDE>
__device__ __forceinline__
void load_fragment_ldmatrix(FragmentA& frag, const __half* smem_ptr) {
int lane = threadIdx.x & 31;
int tile_id = lane >> 3;
int row_in_tile = lane & 7;
int row = (tile_id & 1) * 8 + row_in_tile;
int col = (tile_id >> 1) * 8;
uint32_t addr = __cvta_generic_to_shared(smem_ptr + row * STRIDE + col);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 {%0,%1,%2,%3}, [%4];\n"
: "=r"(frag.reg[0]), "=r"(frag.reg[1]),
"=r"(frag.reg[2]), "=r"(frag.reg[3])
: "r"(addr)
);
}
Loading Fragment B with ldmatrix.x2.trans:
Fragment B is 16×8 (K×N), stored row-major in shared memory (K contiguous along rows). But mma.sync expects B in column-major register layout. The .trans modifier handles this—it transposes each 8×8 tile during the load.
The 16×8 matrix decomposes into two 8×8 tiles stacked vertically (rows 0–7 and rows 8–15). Only 16 of the 32 lanes provide meaningful addresses; lanes 16–31 wrap via lane & 15 (their addresses must be valid but are effectively ignored by hardware since we’re only loading 2 tiles):
16×8 B FRAGMENT → TWO 8×8 TILES
══════════════════════════════════════════════════════
columns 0-7
┌──────────────┐
rows │ tile 0 │
0-7 │ lanes 0-7 │
├──────────────┤
rows │ tile 1 │
8-15 │ lanes 8-15 │
└──────────────┘
Lanes 16-31: wrap to (lane & 15), provide valid but redundant addresses
.trans modifier: each 8×8 tile is transposed during the load, so
row-major data in smem ends up in the column-major register layout
that mma.sync expects.
template<int STRIDE>
__device__ __forceinline__
void load_fragment_ldmatrix(FragmentB& frag, const __half* smem_ptr) {
int lane = threadIdx.x & 31;
int row = lane & 15;
uint32_t addr = __cvta_generic_to_shared(smem_ptr + row * STRIDE);
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {%0,%1}, [%2];\n"
: "=r"(frag.reg[0]), "=r"(frag.reg[1])
: "r"(addr)
);
}
The .trans modifier is essential. Without it, we’d need to either store B column-major in shared memory (complicating the global→shared loads, which are naturally row-major) or manually transpose in registers. The hardware does it for free.
Direct load vs. ldmatrix — why the numbers are surprising:
You might expect ldmatrix to blow past direct loads. After all, we’re replacing 8 individual LDS.16 instructions per thread with a single warp-collective instruction. But the benchmark tells a different story:
| Kernel | TFLOPS | % cuBLAS |
|---|---|---|
| 01a_MMADirect | 75 | 26% |
| 01b_MMALdmatrix | 73 | 25% |
They’re essentially identical—ldmatrix is even marginally slower. The reason: shared memory bank conflicts dominate everything at this stage. Whether you issue 8 scalar loads or one ldmatrix.x4, if the underlying bank access pattern is conflicted, you’re still serialized. With BK=64 and no swizzle, the A tile has 128-byte rows—a multiple of the 128-byte bank cycle—so every ldmatrix lane in the same group hits the same bank. The instruction is faster in isolation, but the bank conflict penalty erases the gain.
This is the core lesson: ldmatrix is a necessary but not sufficient condition for high performance. It unlocks its potential only when paired with a conflict-free memory layout. That’s what kernel 02 provides.
Performance: 73 TFLOPS at N=8192 (25% of cuBLAS)
Kernel 02: XOR Swizzle
This is where the PTX approach pays off. XOR swizzle rearranges shared memory addresses so that lanes which would collide on the same bank get scattered across different banks. The concept was explained in the padding section of the WMMA post, but here we can implement the proper solution: instead of wasting capacity on padding, we XOR the byte offset with bits derived from the row index.
We follow CUTLASS’s Swizzle<B, M, S> convention:
template<int B, int M, int S>
struct Swizzle {
static constexpr int MASK = (1 << B) - 1;
__device__ __forceinline__
static int apply(int byte_offset) {
return byte_offset ^ (((byte_offset >> (M + S)) & MASK) << M);
}
};
The parameters: B controls how many bits to XOR (2^B rows differentiated), M is the destination bit position (must be ≥ 4 for ldmatrix’s 16-byte alignment), and S is the distance from M to the source bits. We derive them from tile dimensions:
constexpr int M_PARAM = 4; // ldmatrix requires 16-byte alignment
constexpr int S_A = clog2(BK * 2) - M_PARAM; // BK=64 → S=3
constexpr int B_A = min(S_A, 3); // B=3 → 8 rows differentiated
With BK=64 (128 bytes per row), this gives Swizzle<3, 4, 3>: XOR bits 7–5 of the byte offset with bits 10–8 (the row bits), placed at bits 6–4 (the bank selection bits). Different rows land in different banks.
Swizzle is applied in two places. On the write side, cp.async stores to the swizzled destination address:
template <int BM, int BK, int NUM_THREADS, typename SwizzleT>
__device__ void loadTileA_async_swizzled(
const __half *A, __half *As, int K, uint tid)
{
for (int i = 0; i < VEC_PER_THREAD; ++i) {
uint idx = tid + i * NUM_THREADS;
uint row = idx / (BK / 8);
uint col8 = idx % (BK / 8);
int byte_offset = (row * BK + col8 * 8) * sizeof(__half);
int swizzled = SwizzleT::apply(byte_offset);
cp_async_cg(
reinterpret_cast<char*>(As) + swizzled,
&A[row * K + col8 * 8]
);
}
}
On the read side, ldmatrix reads from the matching swizzled address:
template<int STRIDE, typename SwizzleT>
__device__ __forceinline__
void load_fragment_ldmatrix_swizzled(FragmentA& frag, const __half* tile_base,
int row_base, int col_base) {
int lane = threadIdx.x & 31;
int tile_id = lane >> 3;
int row_in_tile = lane & 7;
int row = row_base + (tile_id & 1) * 8 + row_in_tile;
int col = col_base + (tile_id >> 1) * 8;
int byte_offset = (row * STRIDE + col) * sizeof(__half);
int swizzled = SwizzleT::apply(byte_offset);
uint32_t addr = __cvta_generic_to_shared(tile_base) + swizzled;
asm volatile(
"ldmatrix.sync.aligned.m8n8.x4.shared.b16 {%0,%1,%2,%3}, [%4];\n"
: "=r"(frag.reg[0]), "=r"(frag.reg[1]),
"=r"(frag.reg[2]), "=r"(frag.reg[3])
: "r"(addr)
);
}
The same swizzle function applies to the epilogue’s shared memory staging buffer, ensuring the C fragment scatter and subsequent vectorized global stores are also conflict-free.
The results confirm that bank conflicts were the bottleneck all along:
| Kernel | TFLOPS | % cuBLAS |
|---|---|---|
| 01b_MMALdmatrix | 73 | 25% |
| 02_MMASwizzle | 212 | 73% |
A 2.9× jump from a single change. This is the largest single improvement in the entire series. ldmatrix was already issuing efficient warp-collective loads, but the bank conflicts were serializing them. Swizzle removes the serialization and lets the hardware do what it was designed to do.
Performance: 212 TFLOPS at N=8192 (73% of cuBLAS)
Kernel 03: Multi-Stage Pipeline
This is the same idea as the WMMA multi-stage kernel: multiple shared memory buffers allow us to overlap the cp.async load of the next tile with mma.sync compute on the current tile.
The only structural change from WMMA is that all shared memory accesses use the swizzled loaders and the compute loop uses PTX mma.sync instead of wmma::mma_sync. The prologue fills STAGES-1 buffers, and the main loop issues the next tile’s async copy before waiting on the current tile’s data.
extern __shared__ __half smem[];
__half* As = smem;
__half* Bs = smem + STAGES * A_STAGE_SIZE;
// ====== PROLOGUE: fill the pipeline ======
for (int s = 0; s < STAGES - 1 && s < numTiles; ++s) {
loadTileA_async_swizzled<...>(A + s * BK, As + s * A_STAGE_SIZE, K, tid);
loadTileB_async_swizzled<...>(B + s * BK * N, Bs + s * B_STAGE_SIZE, N, tid);
cp_async_commit();
}
// ====== MAIN LOOP ======
int loadTile = STAGES - 1;
for (int tile = 0; tile < numTiles; ++tile) {
int computeStage = tile % STAGES;
// Issue next load while computing current tile
if (loadTile < numTiles) {
int loadStage = loadTile % STAGES;
loadTileA_async_swizzled<...>(
A + loadTile * BK, As + loadStage * A_STAGE_SIZE, K, tid);
loadTileB_async_swizzled<...>(
B + loadTile * BK * N, Bs + loadStage * B_STAGE_SIZE, N, tid);
cp_async_commit();
++loadTile;
}
if (loadTile < numTiles) cp_async_wait<STAGES - 1>();
else cp_async_wait<0>();
__syncthreads();
// Compute on current stage (same inner loop as kernel 02)
computeOnStage(As + computeStage * A_STAGE_SIZE,
Bs + computeStage * B_STAGE_SIZE, acc);
__syncthreads();
}
Performance: 245 TFLOPS at N=8192 (85% of cuBLAS)
Kernel 04: Software Pipelining
Again, the same idea as the WMMA software pipelining kernel: double-buffer the register fragments and interleave ldmatrix loads with mma.sync compute within the inner K-loop. The async direct memory access (DMA) for the next tile is issued at the midpoint of the K-loop.
The execution timeline for each tile (BK=64, K_STEPS=4):
k=1: ldmatrix frag[1], mma frag[0]
k=2: ldmatrix frag[0], mma frag[1], cp.async next tile ← midpoint
k=3: ldmatrix frag[1], mma frag[0]
barrier
ldmatrix next.frag[0], mma frag[1] ← cross-tile overlap
// Double-buffered fragments
FragmentA a_frag[2][MMA_M_TILES];
FragmentB b_frag[2][MMA_N_TILES];
// ====== PROLOGUE: fill pipeline ======
for (int s = 0; s < STAGES - 1 && s < numTiles; ++s) {
loadTileA_async_swizzled<...>(A + s * BK, As + s * A_STAGE_SIZE, K, tid);
loadTileB_async_swizzled<...>(B + s * BK * N, Bs + s * B_STAGE_SIZE, N, tid);
cp_async_commit();
}
cp_async_wait<0>();
__syncthreads();
// Load initial k=0 fragments from stage 0
loadFragments(a_frag[0], b_frag[0], As, Bs, /*k=*/0);
int loadTile = STAGES - 1;
// ====== MAIN LOOP ======
for (int tile = 0; tile < numTiles; ++tile) {
const int stage = tile % STAGES;
const __half* As_tile = As + stage * A_STAGE_SIZE;
const __half* Bs_tile = Bs + stage * B_STAGE_SIZE;
// Phase 1: load k+1 fragments, MMA on k (k = 1..K_STEPS-1)
for (int k = 1; k < K_STEPS; ++k) {
loadFragments(a_frag[k % 2], b_frag[k % 2], As_tile, Bs_tile, k);
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
mma_sync(acc[m][n], a_frag[(k-1) % 2][m], b_frag[(k-1) % 2][n]);
// Issue next tile's async DMA at midpoint
if (k == K_STEPS / 2 && loadTile < numTiles) {
int loadStage = loadTile % STAGES;
loadTileA_async_swizzled<...>(
A + loadTile * BK, As + loadStage * A_STAGE_SIZE, K, tid);
loadTileB_async_swizzled<...>(
B + loadTile * BK * N, Bs + loadStage * B_STAGE_SIZE, N, tid);
cp_async_commit();
++loadTile;
}
}
if (loadTile < numTiles) cp_async_wait<STAGES - 2>();
else cp_async_wait<0>();
__syncthreads();
// Phase 2: load k=0 of NEXT tile, MMA on last k of CURRENT tile
if (tile + 1 < numTiles) {
int nextStage = (tile + 1) % STAGES;
loadFragments(a_frag[0], b_frag[0],
As + nextStage * A_STAGE_SIZE,
Bs + nextStage * B_STAGE_SIZE, /*k=*/0);
}
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
mma_sync(acc[m][n], a_frag[(K_STEPS-1) % 2][m],
b_frag[(K_STEPS-1) % 2][n]);
}
Performance: 255 TFLOPS at N=8192 (88% of cuBLAS)
Kernel 05: Block Swizzle
The final kernel adds block swizzle for L2 cache locality—identical to the WMMA final kernel. Adjacent blocks in the 1D grid index are mapped to the same column group so they share B tiles in L2. The linearized grid with column-first traversal within each group:
if constexpr (USE_SWIZZLE) {
const uint numBlocksM = (M + BM - 1) / BM;
const uint numBlocksN = (N + BN - 1) / BN;
const uint numBlocksInGroup = BLOCK_STRIDE * numBlocksN;
const uint groupId = blockIdx.x / numBlocksInGroup;
const uint firstBlockM = groupId * BLOCK_STRIDE;
const uint groupSizeM = min(numBlocksM - firstBlockM, (uint)BLOCK_STRIDE);
blockM = firstBlockM + (blockIdx.x % groupSizeM);
blockN = (blockIdx.x % numBlocksInGroup) / groupSizeM;
}
The block swizzle benefit is marginal at N=8192 (256 vs 255 TFLOPS) but becomes more pronounced at N=16384 (242 vs 237 TFLOPS) where L2 pressure is higher.
Performance: 256 TFLOPS at N=8192 (88% of cuBLAS)
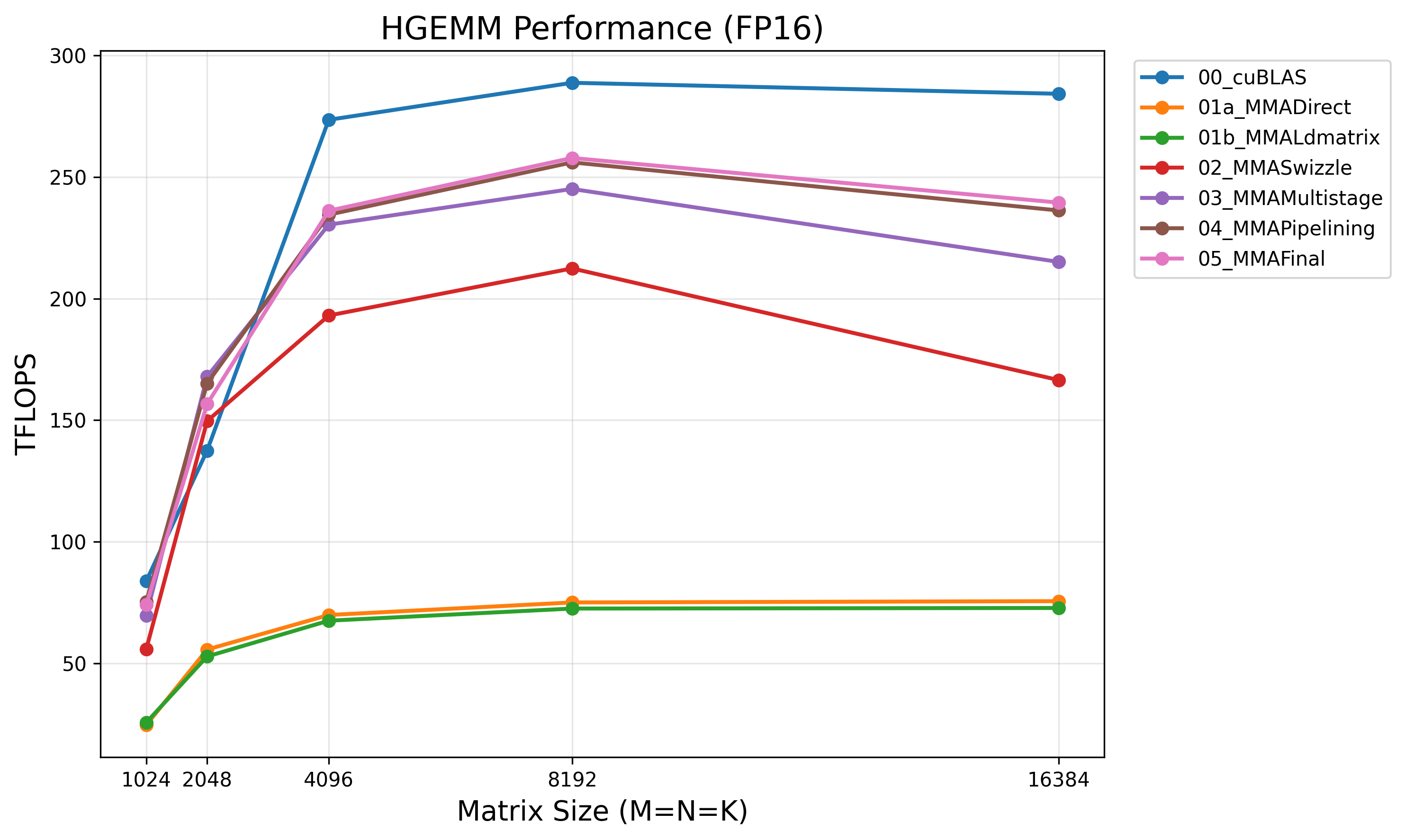
Results
Benchmarked on NVIDIA A100-SXM4-40GB at N=8192:
| Kernel | TFLOPS | % cuBLAS |
|---|---|---|
| cuBLAS (FP16) | 289 | 100% |
| 01a_MMADirect | 75 | 26% |
| 01b_MMALdmatrix | 73 | 25% |
| 02_MMASwizzle | 212 | 73% |
| 03_MMAMultistage | 245 | 85% |
| 04_MMAPipelining | 255 | 88% |
| 05_MMAFinal | 256 | 88% |
The Remaining Gap
Our best kernel reaches 88% of cuBLAS. The remaining ~12% gap likely comes from:
- Optimized instruction scheduling: Hand-tuned SASS-level ordering of MMA, ldmatrix, and cp.async instructions to eliminate pipeline bubbles that the compiler misses.
- Register-level optimizations: Careful register allocation to minimize spills, especially at large tile sizes where register pressure is high.
- Per-size tuning tables: cuBLAS ships with exhaustive configurations for every matrix size, while our autotuner explores a small search space.
Conclusion
Dropping from WMMA to PTX mma.sync on A100 takes us from 80% to 88% of cuBLAS. The key takeaways:
- Explicit fragment layout: Knowing the register-to-matrix mapping enables both direct loads (educational) and ldmatrix (efficient)
- ldmatrix + swizzle as a pair:
ldmatrixalone doesn’t help—it needs conflict-free shared memory addressing to reach its potential. Together they deliver a 2.9× speedup - XOR swizzle: Eliminates bank conflicts with zero shared memory capacity overhead
- Same pipeline structure: Async copy, multi-stage, and software pipelining carry over unchanged from WMMA—the PTX level only changes the inner load/compute primitives