Tensor Core HGEMM: A Progressive Optimization Guide Using WMMA
Introduction
The previous post optimized single-precision GEMM using CUDA cores, reaching 89% of cuBLAS performance. But modern deep learning runs on FP16, and modern GPUs have dedicated tensor cores that deliver 4-16× higher throughput than CUDA cores for matrix operations.
This post implements half-precision GEMM (HGEMM) using NVIDIA’s WMMA (Warp Matrix Multiply-Accumulate) API, progressing from a naive tensor core kernel to 72% of cuBLAS performance on an A100. WMMA provides a high-level abstraction over tensor cores that handles the hardware complexity while still exposing the key optimization opportunities. The benchmark code is available in this repository.
A follow-up post will explore the lower-level PTX mma.sync instructions to close the remaining gap.
Tensor Cores and the WMMA API
Tensor cores are specialized hardware units that compute small matrix multiply-accumulate operations in a single cycle. The fundamental operation is:
\[D = A \times B + C\]where A, B, C, and D are small matrix tiles. The supported tile dimensions and data types depend on the GPU architecture. NVIDIA provides support across multiple precisions:
- FP16 / BF16: Half-precision for inference and training
- TF32: 19-bit format for FP32-like range with tensor core throughput (Ampere+)
- FP64: Double precision tensor cores (A100+, limited throughput)
- INT8 / INT4: Integer formats for quantized inference
Each precision supports specific matrix shapes (m×n×k combinations). For example, FP16 on Ampere supports 16×16×16, 32×8×16, and 8×32×16 tile shapes. See the CUDA Programming Guide for the complete list of supported element types and sizes.
This post focuses on FP16 with 16×16×16 tiles, a common configuration for square matrices. On A100, each SM contains 3rd generation tensor cores, and a single wmma::mma_sync instruction computes 16×16×16 = 4096 multiply-add operations (8192 FLOPs) per warp.
The WMMA API abstracts tensor cores through fragments: opaque containers that hold matrix tiles distributed across a warp’s 32 threads.
#include <mma.h>
using namespace nvcuda;
// Declare fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, __half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, __half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, __half> acc_frag;
// Load tiles from memory
wmma::load_matrix_sync(a_frag, A_ptr, lda);
wmma::load_matrix_sync(b_frag, B_ptr, ldb);
wmma::fill_fragment(acc_frag, 0.0f);
// Execute tensor core MMA
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
// Store result
wmma::store_matrix_sync(C_ptr, acc_frag, ldc, wmma::mem_row_major);
The compiler maps these operations to the underlying tensor core instructions. Our job is to feed the tensor cores efficiently by optimizing memory access patterns, which is where all the performance comes from.
Kernel 1: Block Tiling Baseline
The first kernel adapts the SGEMM block tiling strategy for tensor cores. Each threadblock computes a $BM \times BN$ output tile; within the block, each warp computes a $WM \times WN$ sub-tile using multiple $16 \times 16$ WMMA operations.
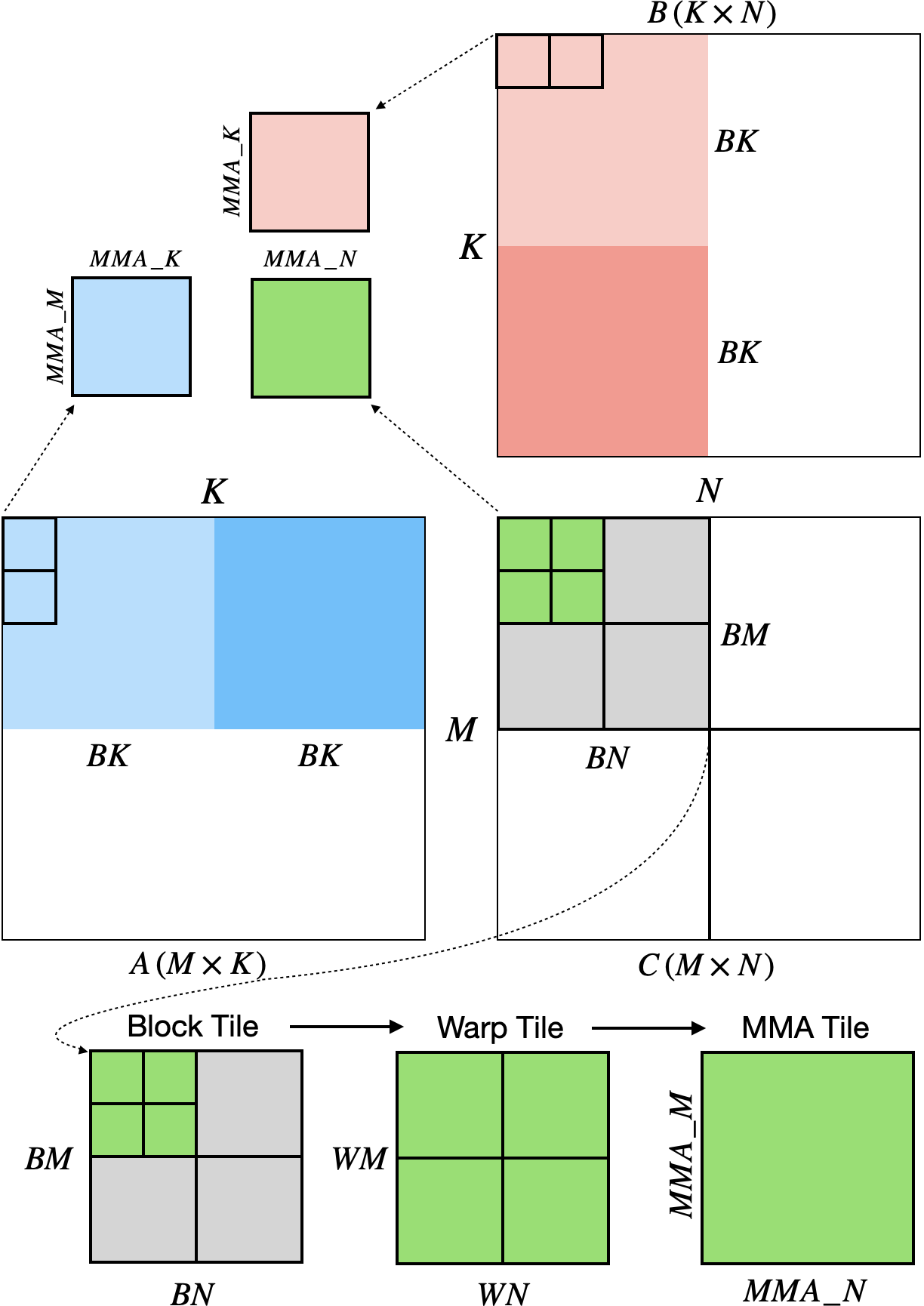
The diagram above shows the high-level structure. Let’s trace through the math with concrete numbers:
TILING HIERARCHY (BM=128, BN=128, WM=32, WN=32)
═══════════════════════════════════════════════════════════════
BLOCK TILE (128 × 128)
──────────────────────
BN = 128
◄────────────────────────────────────►
┌────────┬────────┬────────┬────────┐
│ Warp 0 │ Warp 1 │ Warp 2 │ Warp 3 │ 32
├────────┼────────┼────────┼────────┤
│ Warp 4 │ Warp 5 │ Warp 6 │ Warp 7 │ 32
BM=128 ├────────┼────────┼────────┼────────┤
│ Warp 8 │ Warp 9 │Warp 10 │Warp 11 │ 32
├────────┼────────┼────────┼────────┤
│Warp 12 │Warp 13 │Warp 14 │Warp 15 │ 32
└────────┴────────┴────────┴────────┘
32 32 32 32
→ 16 warps = 512 threads per block
→ Each warp owns a 32×32 output region
WARP TILE (32 × 32) ◄── zooming into one warp
───────────────────
WN = 32
◄────────────────►
┌───────┬────────┐
│ MMA │ MMA │ 16
WM=32 ├───────┼────────┤
│ MMA │ MMA │ 16
└───────┴────────┘
16 16
→ 4 MMA operations per warp
→ Each MMA: 16×16×16 = 4096 FMAs
FRAGMENT DISTRIBUTION ◄── inside one MMA
─────────────────────
A 16×16 fragment holds 256 values, but no single
thread sees the whole matrix:
Thread 0 → elements [?, ?, ?, ?, ?, ?, ?, ?] ┐
Thread 1 → elements [?, ?, ?, ?, ?, ?, ?, ?] │
... ├─ 32 threads × 8 = 256 ✓
Thread 31 → elements [?, ?, ?, ?, ?, ?, ?, ?] ┘
The layout is opaque. WMMA handles distribution internally.
We just call load_matrix_sync() and mma_sync().
═══════════════════════════════════════════════════════════════
The key insight: we never manipulate individual matrix elements. WMMA fragments are opaque containers. We load them from shared memory, execute MMA operations, and store the results. The hardware handles the complex data distribution across threads.
The kernel structure is shown below. To keep things focused, I’ve moved the shared memory loading and epilogue logic into helper functions (loadTileA_scalar, loadTileB_scalar, and epilogueAndStore). The full implementations are in the repository.
template <int BM, int BN, int BK, int WM, int WN>
__global__ void wmma_block_tiling(
int M, int N, int K, __half alpha,
const __half *A, const __half *B, __half beta, __half *C)
{
constexpr int MMA_M = 16, MMA_N = 16, MMA_K = 16;
constexpr int MMA_M_TILES = WM / MMA_M;
constexpr int MMA_N_TILES = WN / MMA_N;
constexpr int WARPS_M = BM / WM;
constexpr int WARPS_N = BN / WN;
__shared__ __half As[BM * BK];
__shared__ __half Bs[BK * BN];
const uint warpId = threadIdx.x / 32;
const uint warpM = warpId / WARPS_N;
const uint warpN = warpId % WARPS_N;
// Initialize accumulators
wmma::fragment<wmma::accumulator, 16, 16, 16, __half> acc[MMA_M_TILES][MMA_N_TILES];
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
wmma::fill_fragment(acc[m][n], __float2half(0.0f));
for (int tileK = 0; tileK < K; tileK += BK) {
// Load tiles with scalar loads (one element per thread)
loadTileA_scalar<BM, BK, NUM_THREADS>(A, As, K, tid);
loadTileB_scalar<BK, BN, NUM_THREADS>(B, Bs, N, tid);
__syncthreads();
// Process BK elements in MMA_K chunks
for (int innerK = 0; innerK < BK; innerK += MMA_K) {
wmma::fragment<wmma::matrix_a, 16, 16, 16, __half, wmma::row_major>
a_frag[MMA_M_TILES];
wmma::fragment<wmma::matrix_b, 16, 16, 16, __half, wmma::row_major>
b_frag[MMA_N_TILES];
// Load A fragments for this warp
for (int m = 0; m < MMA_M_TILES; ++m) {
const __half *As_ptr = &As[(warpM * WM + m * MMA_M) * BK + innerK];
wmma::load_matrix_sync(a_frag[m], As_ptr, BK);
}
// Load B fragments for this warp
for (int n = 0; n < MMA_N_TILES; ++n) {
const __half *Bs_ptr = &Bs[innerK * BN + warpN * WN + n * MMA_N];
wmma::load_matrix_sync(b_frag[n], Bs_ptr, BN);
}
// Tensor core MMA
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
wmma::mma_sync(acc[m][n], a_frag[m], b_frag[n], acc[m][n]);
}
__syncthreads();
}
// Store results
epilogueAndStore(acc, C, N, alpha, beta, warpM, warpN);
}
The loadTileA_scalar function reveals our first bottleneck. Each thread loads just one __half element at a time:
template <int BM, int BK, int NUM_THREADS>
__device__ void loadTileA_scalar(const __half *A, __half *As, int K, uint tid)
{
constexpr int TOTAL_ELEMENTS = BM * BK;
constexpr int ELEMENTS_PER_THREAD = TOTAL_ELEMENTS / NUM_THREADS;
for (int i = 0; i < ELEMENTS_PER_THREAD; ++i) {
uint idx = tid + i * NUM_THREADS;
uint row = idx / BK;
uint col = idx % BK;
As[row * BK + col] = A[row * K + col]; // Single __half load
}
}
The bottleneck is scalar memory loads. Each thread loads one __half at a time, but a float4 can load 8 halves in one instruction.
We’re leaving 87.5% of potential memory throughput on the table.
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 01_WMMABlockTiling | 3.23 ms | 42.6 | 16% |
Kernel 2: Vectorized Loads
FP16 elements are only 2 bytes. To maximize memory bandwidth, we use float4 loads (16 bytes = 8 half elements) for coalesced 128-byte transactions:
template <int BM, int BK, int NUM_THREADS>
__device__ void loadTileA_vec4(const __half *A, __half *As, int K, uint tid)
{
constexpr int TOTAL_VEC = (BM * BK) / 8; // 8 halves per float4
constexpr int VEC_PER_THREAD = TOTAL_VEC / NUM_THREADS;
for (int i = 0; i < VEC_PER_THREAD; ++i) {
uint idx = tid + i * NUM_THREADS;
uint row = idx / (BK / 8);
uint col8 = idx % (BK / 8);
// Load 8 halves at once via float4
float4 val = reinterpret_cast<const float4*>(&A[row * K + col8 * 8])[0];
reinterpret_cast<float4*>(&As[row * BK + col8 * 8])[0] = val;
}
}
Vectorization nearly doubles performance by utilizing full memory transaction width.
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 01_WMMABlockTiling | 3.23 ms | 42.6 | 16% |
| 02_WMMAVectorized | 1.85 ms | 74.3 | 27% |
Kernel 3: Asynchronous Copy
On SM80+ architectures (Ampere and later), cp.async copies directly from global to shared memory without staging through registers. This reduces register pressure and enables better latency hiding. It also sets us up nicely for multi-stage pipelining, which we’ll implement later.
template <int BM, int BK, int NUM_THREADS>
__device__ void loadTileA_async(const __half *A, __half *As, int K, uint tid)
{
constexpr int VEC_PER_THREAD = (BM * BK) / 8 / NUM_THREADS;
for (int i = 0; i < VEC_PER_THREAD; ++i) {
uint idx = tid + i * NUM_THREADS;
uint row = idx / (BK / 8);
uint col8 = idx % (BK / 8);
__pipeline_memcpy_async(
&As[row * BK + col8 * 8],
&A[row * K + col8 * 8],
sizeof(float4)
);
}
}
The pipeline API commits and waits for async copies:
loadTileA_async<BM, BK, NUM_THREADS>(A, As, K, tid);
loadTileB_async<BK, BN, NUM_THREADS>(B, Bs, N, tid);
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 02_WMMAVectorized | 1.85 ms | 74.3 | 27% |
| 03_WMMAAsync | 1.66 ms | 82.6 | 30% |
Kernel 4: Shared Memory Padding
Shared memory is organized into 32 banks of 4 bytes each. When multiple threads access addresses that map to the same bank, the accesses serialize (bank conflicts). With FP16, 8 consecutive elements span 16 bytes = 4 banks, and the 16×16 WMMA tile layout creates systematic conflicts.
Since we don’t know exactly how WMMA accesses shared memory internally (it’s opaque), padding is an educated guess based on knowing that it generally helps with bank conflicts. We pad by 8 elements (16 bytes) since this maintains the 16-byte alignment required for our vectorized cp.async copies while shifting successive rows to different banks.
constexpr int SMEM_PAD = 8;
constexpr int A_STRIDE = BK + SMEM_PAD; // 32 + 8 = 40
constexpr int B_STRIDE = BN + SMEM_PAD;
__shared__ __half As[BM * A_STRIDE];
__shared__ __half Bs[BK * B_STRIDE];
The trade-off is wasted shared memory. For a BM=128, BK=32 tile, we go from 128×32×2 = 8KB to 128×40×2 = 10KB. That’s 25% overhead per tile. Multiply by 2 matrices and multiple pipeline stages, and it adds up. A better alternative is XOR-based swizzling, which eliminates bank conflicts without padding overhead. We can’t use swizzle patterns with WMMA (the API doesn’t expose the required control), but we’ll explore this in the PTX mma.sync follow-up.
Loading stores to the padded layout:
// Store with padded stride
__pipeline_memcpy_async(
&As[row * A_STRIDE + col8 * 8], // Padded stride
&A[row * K + col8 * 8], // Natural stride
sizeof(float4)
);
Fragment loads also use the padded stride:
wmma::load_matrix_sync(a_frag[m], As_ptr, A_STRIDE); // Lead dimension = padded stride
This reduces bank conflicts and nearly doubles our performance:
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 03_WMMAAsync | 1.66 ms | 82.6 | 30% |
| 04_WMMAPadded | 0.89 ms | 154.5 | 57% |
Kernel 5: Multi-Stage Pipeline
With single buffering, computation waits for memory. A multi-stage pipeline keeps STAGES-1 loads in flight while computing on the current tile. The following diagrams show how pipelining overlaps memory and compute:
NO PIPELINING
Memory and compute are serialized. Compute stalls waiting for each load.
Cycle: 1 2 3 4 5 6 7 8 9 ...
──────────────────────────────────────────────────────────
Memory: [L0] [L1] [L2] [L3] [L4]
Compute: [C0] [C1] [C2] [C3] ...
2-STAGE PIPELINE
Prologue loads 1 tile. Main loop overlaps next load with current compute.
Cycle: 1 2 3 4 5 6 7
────────────────────────────────────────────
Memory: [L0] [L1] [L2] [L3] [L4] [L5]
Compute: [C0] [C1] [C2] [C3] [C4] [C5]
└pro┘ └────────── main loop ───────────┘
3-STAGE PIPELINE
Prologue loads 2 tiles. Deeper buffer hides more memory latency.
Cycle: 1 2 3 4 5 6 7 8
─────────────────────────────────────────────────
Memory: [L0] [L1] [L2] [L3] [L4] [L5]
Compute: [C0] [C1] [C2] [C3] [C4] [C5]
└─prologue─┘ └─────────── main loop ───────────┘
The kernel maintains circular buffers and tracks which stage to compute vs. load:
__shared__ __half As[STAGES][BM * A_STRIDE];
__shared__ __half Bs[STAGES][BK * B_STRIDE];
// Prologue: fill pipeline
for (int s = 0; s < STAGES - 1 && s < numTiles; ++s) {
loadTileA_async_padded<BM, BK, A_STRIDE, NUM_THREADS>(A + s * BK, As[s], K, tid);
loadTileB_async_padded<BK, BN, B_STRIDE, NUM_THREADS>(B + s * BK * N, Bs[s], N, tid);
__pipeline_commit();
}
// Main loop
int loadTile = STAGES - 1;
for (int tile = 0; tile < numTiles; ++tile) {
int computeStage = tile % STAGES;
// Prefetch next tile
if (loadTile < numTiles) {
int loadStage = loadTile % STAGES;
loadTileA_async_padded(..., As[loadStage], ...);
loadTileB_async_padded(..., Bs[loadStage], ...);
__pipeline_commit();
++loadTile;
}
// Wait for compute stage (STAGES-1 loads remain in flight)
__pipeline_wait_prior(STAGES - 1);
__syncthreads();
// Compute on As[computeStage], Bs[computeStage]
// ...
}
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 04_WMMAPadded | 0.89 ms | 154.5 | 57% |
| 05_WMMAMultistage | 0.73 ms | 189.0 | 69% |
Kernel 6: Fragment Double Buffering
Multi-stage pipelining overlaps global to shared transfers. We can also overlap shared to register transfers by double-buffering the WMMA fragments:
// Double-buffered fragments
wmma::fragment<wmma::matrix_a, 16, 16, 16, __half, wmma::row_major> a_frag[2][MMA_M_TILES];
wmma::fragment<wmma::matrix_b, 16, 16, 16, __half, wmma::row_major> b_frag[2][MMA_N_TILES];
int frag_load = 0;
int frag_compute = 1;
// Prologue: load first fragments
for (int m = 0; m < MMA_M_TILES; ++m)
wmma::load_matrix_sync(a_frag[frag_load][m], As_ptr_k0, A_STRIDE);
for (int n = 0; n < MMA_N_TILES; ++n)
wmma::load_matrix_sync(b_frag[frag_load][n], Bs_ptr_k0, B_STRIDE);
// Main inner loop
for (int innerK = 0; innerK < BK; innerK += MMA_K) {
frag_load ^= 1; // Swap buffers
frag_compute ^= 1;
// Load NEXT fragments (overlapped with compute)
if (innerK + MMA_K < BK) {
for (int m = 0; m < MMA_M_TILES; ++m)
wmma::load_matrix_sync(a_frag[frag_load][m], As_ptr_next, A_STRIDE);
for (int n = 0; n < MMA_N_TILES; ++n)
wmma::load_matrix_sync(b_frag[frag_load][n], Bs_ptr_next, B_STRIDE);
}
// Compute with CURRENT fragments
for (int m = 0; m < MMA_M_TILES; ++m)
for (int n = 0; n < MMA_N_TILES; ++n)
wmma::mma_sync(acc[m][n], a_frag[frag_compute][m],
b_frag[frag_compute][n], acc[m][n]);
}
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 05_WMMAMultistage | 0.73 ms | 189.0 | 69% |
| 06_WMMADoubleBuffer | 0.72 ms | 189.8 | 70% |
The gains from fragment double buffering are minimal here because the inner loop is fully unrolled and the compiler already schedules loads well.
Kernel 7: Dynamic Shared Memory
Static shared memory is limited to 48KB on A100. For larger tiles or more pipeline stages, we use dynamic shared memory (up to 164KB on A100):
extern __shared__ __half smem[];
__half* As = smem;
__half* Bs = smem + STAGES * A_STAGE_SIZE;
At launch, configure and allocate:
cudaFuncSetAttribute(
wmma_dynsmem<BM, BN, BK, WM, WN, STAGES>,
cudaFuncAttributeMaxDynamicSharedMemorySize,
SMEM_SIZE
);
wmma_dynsmem<<<grid, block, SMEM_SIZE>>>(...);
This enables larger configurations that wouldn’t fit in static shared memory.
| Kernel | N=4096 Time | TFLOPS | % cuBLAS |
|---|---|---|---|
| 06_WMMADoubleBuffer | 0.72 ms | 189.8 | 70% |
| 07_WMMADynSmem | 0.74 ms | 186.8 | 69% |
We don’t see any benefit at this size since we’re already using efficient configurations within the 48KB static limit. The real benefit comes in the final kernel where autotuning can explore configurations that require more shared memory.
Kernel 8: Final Optimizations
The final kernel combines all optimizations plus additional refinements:
Zig-zag MMA order: When iterating over MMA tiles, we alternate the N direction on odd M rows. This maximizes fragment reuse: the last B fragment used at the end of one row is the first one needed at the start of the next.
Access pattern (MMA_M_TILES=4, MMA_N_TILES=4):
Sequential order: Zig-zag order:
m=0: n=0,1,2,3 m=0: n=0,1,2,3
m=1: n=0,1,2,3 m=1: n=3,2,1,0 ← reversed
m=2: n=0,1,2,3 m=2: n=0,1,2,3
m=3: n=0,1,2,3 m=3: n=3,2,1,0 ← reversed
With zig-zag: the last B fragment used at the end of m=0 is b_frag[3].
The first B fragment needed at the start of m=1 is also b_frag[3].
It's already in registers!
for (int m = 0; m < MMA_M_TILES; ++m) {
for (int n = 0; n < MMA_N_TILES; ++n) {
int n_idx = (m % 2) ? (MMA_N_TILES - 1 - n) : n; // Zig-zag
wmma::mma_sync(acc[m][n_idx], a_frag[frag_compute][m],
b_frag[frag_compute][n_idx], acc[m][n_idx]);
}
}
Vectorized epilogue: Reuse A/B shared memory for C tile, then copy to global with float4 stores for better coalescing.
Block swizzling: Remap block indices to improve L2 cache locality. Instead of using a 2D grid, we use a 1D grid and remap the linear block index to (blockM, blockN) coordinates. Blocks are processed in groups of GROUP_SIZE_M rows before advancing to the next column group:
STANDARD 2D GRID (row-major execution)
blockIdx.x →
0 1 2 3
┌───────┬───────┬───────┬───────┐
0 │ 0 │ 1 │ 2 │ 3 │
├───────┼───────┼───────┼───────┤
1 │ 4 │ 5 │ 6 │ 7 │
blockIdx.y ├───────┼───────┼───────┼───────┤
↓ 2 │ 8 │ 9 │ 10 │ 11 │
├───────┼───────┼───────┼───────┤
3 │ 12 │ 13 │ 14 │ 15 │
└───────┴───────┴───────┴───────┘
Execution: 0→1→2→3→4→5→... (row by row)
Problem: Block 4 needs B[:,0] but it may be evicted by B[:,1], B[:,2], B[:,3].
SWIZZLED 1D GRID (GROUP_SIZE_M=2)
blockIdx.x →
0 1 2 3
┌───────┬───────*───────┬───────┐
0 │ 0 │ 2 * 4 │ 6 │
├───────┼───────*───────┼───────┤
1 │ 1 │ 3 * 5 │ 7 │
blockIdx.y * * * * * * * * * * * * * * * * *
↓ 2 │ 8 │ 10 * 12 │ 14 │
├───────┼───────*───────┼───────┤
3 │ 9 │ 11 * 13 │ 15 │
└───────┴───────*───────┴───────┘
Execution: 0→1→2→3→4→5→... (down columns within each group)
Blocks 0,1 share B[:,0]. Blocks 2,3 share B[:,1]. Better L2 reuse.
if constexpr (USE_SWIZZLE) {
const uint num_blocks_m = (M + BM - 1) / BM;
const uint num_blocks_n = (N + BN - 1) / BN;
const uint num_blocks_in_group = GROUP_SIZE_M * num_blocks_n;
const uint bid = blockIdx.x; // 1D block index
const uint group_id = bid / num_blocks_in_group;
const uint first_block_m = group_id * GROUP_SIZE_M;
const uint group_size_m = min(num_blocks_m - first_block_m, (uint)GROUP_SIZE_M);
blockM = first_block_m + (bid % group_size_m);
blockN = (bid % num_blocks_in_group) / group_size_m;
}
Autotuning
Tile sizes, pipeline stages, and swizzle parameters significantly affect performance. We autotune across configurations:
[Autotune] Testing 9 configurations on 4096x4096x4096...
128x128x32_64x64_S2_swfalse_g8 0.700 ms 196.43 TFLOPS
128x128x32_64x64_S3_swfalse_g8 0.788 ms 174.47 TFLOPS
256x128x32_64x64_S3_swfalse_g8 0.907 ms 151.49 TFLOPS
128x128x32_64x64_S2_swtrue_g8 0.698 ms 197.03 TFLOPS
128x128x32_64x64_S3_swtrue_g8 0.786 ms 174.97 TFLOPS
256x128x32_64x64_S3_swtrue_g8 0.907 ms 151.50 TFLOPS
128x128x32_64x64_S2_swtrue_g16 0.697 ms 197.21 TFLOPS <- Best
128x128x32_64x64_S3_swtrue_g16 0.785 ms 175.06 TFLOPS
256x128x32_64x64_S3_swtrue_g16 0.907 ms 151.47 TFLOPS
[Autotune] Best: 128x128x32_64x64_S2_swtrue_g16 (0.697 ms, 197.21 TFLOPS)
Key findings from autotuning on A100:
- 2-stage pipelines beat 3-stage: deeper pipelines increase register pressure without benefit
- Swizzle helps at large sizes: 197 vs 196 TFLOPS at N=4096, bigger gains at N=8192
- 128×128 blocks dominate: 256×128 blocks underperform despite larger tiles
- GROUP_SIZE_M=8 or 16 both work well depending on matrix size
Results
Benchmarked on NVIDIA A100-SXM4-40GB with N=4096:
| Kernel | Time (ms) | TFLOPS | % cuBLAS |
|---|---|---|---|
| cuBLAS (FP16) | 0.51 | 272.1 | 100% |
| 01_WMMABlockTiling | 3.23 | 42.6 | 16% |
| 02_WMMAVectorized | 1.85 | 74.3 | 27% |
| 03_WMMAAsync | 1.66 | 82.6 | 30% |
| 04_WMMAPadded | 0.89 | 154.5 | 57% |
| 05_WMMAMultistage | 0.73 | 189.0 | 69% |
| 06_WMMADoubleBuffer | 0.72 | 189.8 | 70% |
| 07_WMMADynSmem | 0.74 | 186.8 | 69% |
| 08_WMMAFinal | 0.70 | 195.7 | 72% |
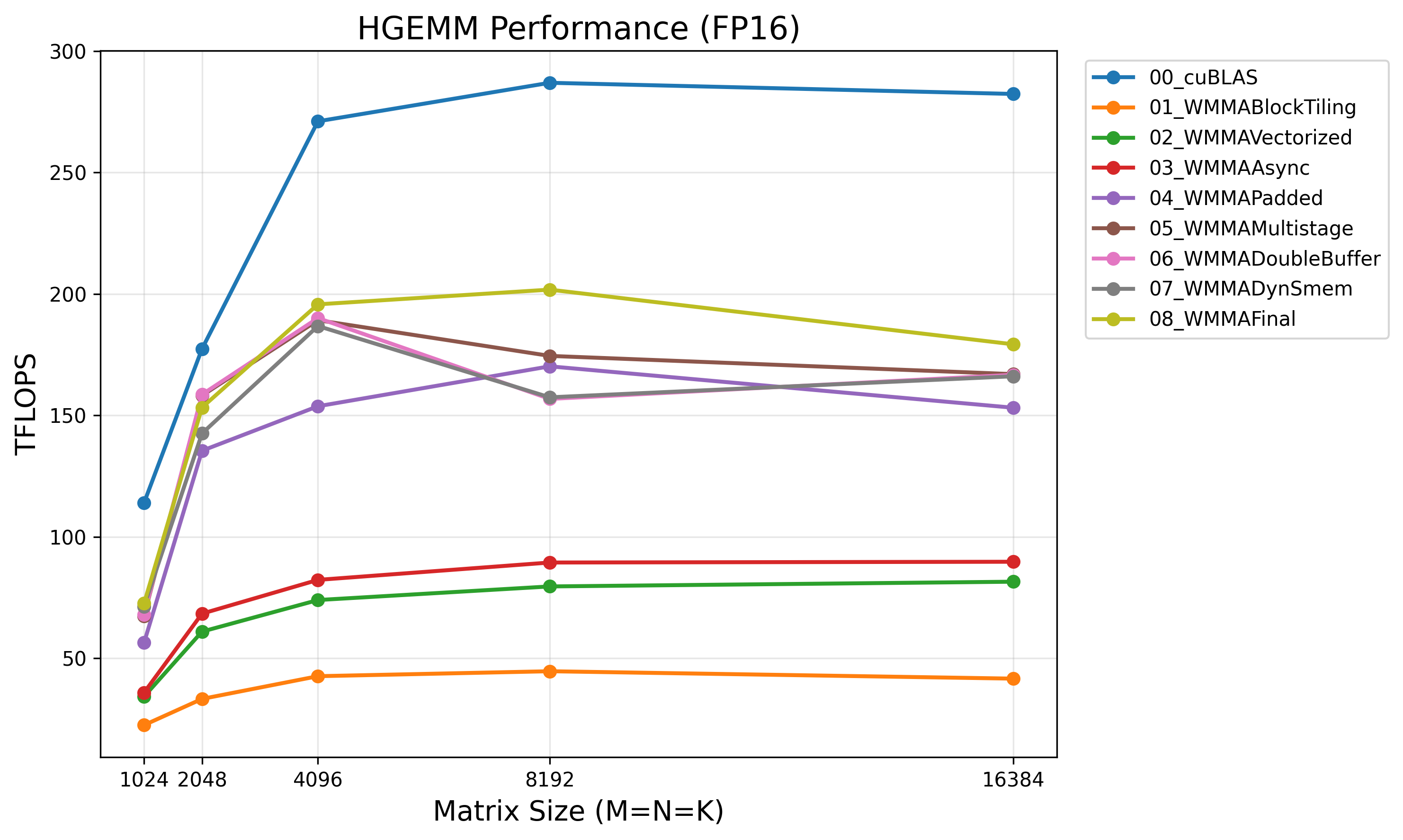
Performance across matrix sizes:
| Size | cuBLAS | Our Kernel | % cuBLAS |
|---|---|---|---|
| 1024 | 113 TFLOPS | 73 TFLOPS | 65% |
| 2048 | 178 TFLOPS | 154 TFLOPS | 87% |
| 4096 | 272 TFLOPS | 196 TFLOPS | 72% |
| 8192 | 285 TFLOPS | 201 TFLOPS | 70% |
| 16384 | 281 TFLOPS | 171 TFLOPS | 61% |
The efficiency varies with matrix size. Our kernel performs best at medium sizes (N=2048, 8192) where tile configurations match well, and the gap widens at very large sizes (N=16384) where cuBLAS’s more advanced techniques dominate.
The Gap to cuBLAS
The remaining ~30% gap comes from techniques beyond WMMA’s abstraction level:
- PTX
mma.syncinstructions: Direct control over tensor core operations, enabling finer instruction scheduling and register management - XOR-based swizzling: Shared memory addressing patterns that eliminate bank conflicts without the 25% padding overhead we’re paying
- Architecture-specific tuning: cuBLAS has years of per-GPU, per-size optimization tables that we can’t match with a simple autotuner
WMMA is a good starting point, but extracting the last bits of performance requires dropping to PTX.
Conclusion
Optimizing tensor core GEMM follows the same principles as CUDA core optimization, with additional considerations:
- Use tensor cores: 4-16× theoretical speedup over CUDA cores for supported precisions
- Vectorize memory access: float4 loads for FP16, matching 128-byte transaction size
- Eliminate bank conflicts: Padding shared memory rows by 8 FP16 elements (or use swizzle in PTX)
- Pipeline memory transfers: Multi-stage async pipeline keeps tensor cores fed
- Autotune configurations: Optimal parameters vary significantly by matrix size and GPU architecture
WMMA provides a clean abstraction that captures 72% of cuBLAS performance on A100. The remaining gap requires lower-level techniques: PTX mma.sync for finer instruction scheduling and XOR-based swizzling to eliminate padding overhead. These will be explored in the follow-up post.