GPU Histogram: From Global Atomics to Shared Memory Privatization
Introduction
Histograms count how often each value appears in a dataset. Given an array of values and a set of bins, we increment the counter for each bin as we encounter matching values. The sequential algorithm is trivial:
for each element x in data:
histogram[x] += 1
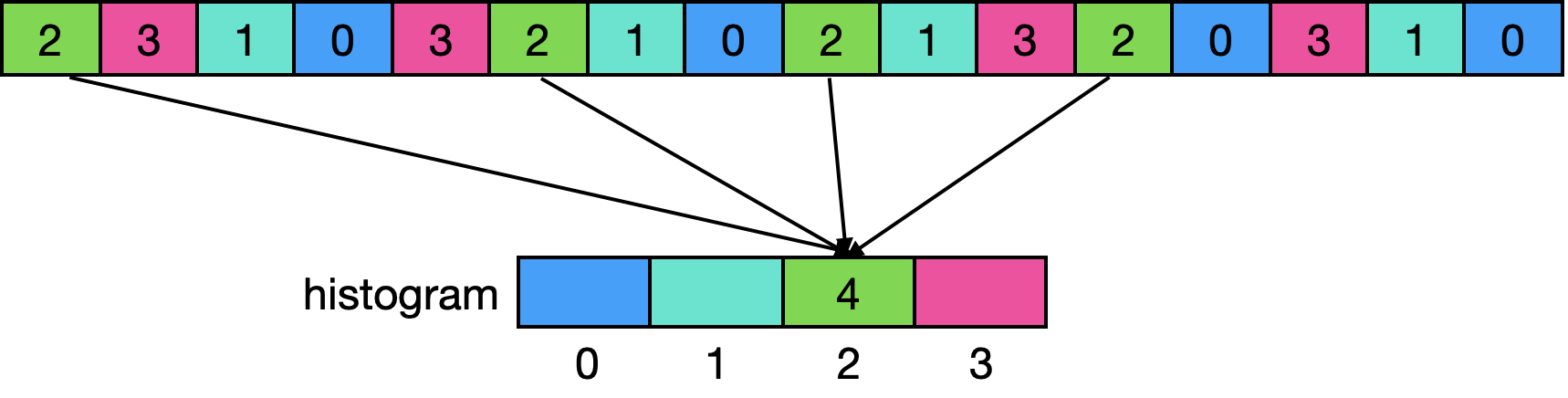
The challenge on GPUs is that the output location depends on the input value. Unlike scan or reduction where we know the output pattern ahead of time, histogram bins are determined at runtime. When thousands of threads simultaneously try to increment the same bin, we face severe contention. An example of basic parallelization of histogram is shown in Figure 1 below.
This post implements a 256-bin histogram from first principles, progressively optimizing from a naive baseline to an implementation that matches CUB’s performance. The benchmark code is available in this repository.
Global Atomics: The Baseline
The most straightforward parallel histogram has each thread read one element and atomically increment the corresponding bin in global memory:
template<int NUM_BINS>
__global__ void HistogramGlobalAtomic(
const unsigned char* __restrict__ data,
int num_elements,
int* __restrict__ histogram)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = gridDim.x * blockDim.x;
for (int i = idx; i < num_elements; i += stride)
{
atomicAdd(&histogram[data[i]], 1);
}
}
The grid-stride loop allows each thread to process multiple elements, and atomicAdd ensures correctness when multiple threads target the same bin.
Let’s see how this performs on an H100 with $2^{30}$ unsigned char elements (1 GB of data):
Experiment Setup
- GPU: H100 (HBM3, ~3.3 TB/s peak)
- BLOCK_SIZE = 512 threads
- Data distribution (uniform random)
- NUM_BINS = 256
| Kernel | Time (ms) | Bandwidth | % Peak |
|---|---|---|---|
| Global Atomic | 276.13 | 3.89 GB/s | 0.1% |
0.1% of peak bandwidth. The problem is contention. With uniform random data across 256 bins and millions of threads, many threads collide on the same bin simultaneously. Each collision serializes the atomic operation, and global memory atomics have high latency (hundreds of cycles). The result is that threads spend most of their time waiting rather than doing useful work.
Shared Memory Privatization
The solution is privatization: give each thread block its own histogram in shared memory. Threads within a block accumulate into the private histogram using fast shared memory atomics, then a single merge step writes the block’s results to global memory.
template<int NUM_BINS>
__global__ void HistogramSharedAtomic(
const unsigned char* __restrict__ data,
int num_elements,
int* __restrict__ histogram)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = gridDim.x * blockDim.x;
// Initialize block-private histogram
__shared__ int histogram_s[NUM_BINS];
for (int bin = threadIdx.x; bin < NUM_BINS; bin += blockDim.x) {
histogram_s[bin] = 0;
}
__syncthreads();
// Accumulate into shared memory
for (int i = idx; i < num_elements; i += stride) {
atomicAdd(&histogram_s[data[i]], 1);
}
__syncthreads();
// Write block histogram to global
for (int bin = threadIdx.x; bin < NUM_BINS; bin += blockDim.x) {
int bin_value = histogram_s[bin];
if (bin_value > 0) {
atomicAdd(&histogram[bin], bin_value);
}
}
}
Shared memory atomics are an order of magnitude faster than global memory atomics. More importantly, contention is now limited to threads within a single block (512 threads) rather than across the entire grid (millions of threads). The final merge performs at most 256 global atomics per block, compared to potentially millions in the naive approach.
| Kernel | Time (ms) | Bandwidth | % Peak |
|---|---|---|---|
| Global Atomic | 276.13 | 3.89 GB/s | 0.1% |
| Shared Atomic | 1.53 | 703.10 GB/s | 21.0% |
A huge improvement, but we’re still only at 21% of peak bandwidth. The bottleneck has shifted from just global atomic contention to shared-memory atomics and memory throughput: we’re loading one byte at a time, which underutilizes the memory system.
Vectorized Loads
Modern GPUs can load 128 bits (16 bytes) in a single transaction. Loading one byte at a time wastes this capability. By using uint4 loads, we can read 16 unsigned char values per memory transaction and process them before moving to the next load:
template<int NUM_BINS>
__global__ void HistogramSharedAtomicVec(
const unsigned char* __restrict__ data,
int num_elements,
int* __restrict__ histogram)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int stride = gridDim.x * blockDim.x;
// Initialize block-private histogram
__shared__ int histogram_s[NUM_BINS];
for (int bin = threadIdx.x; bin < NUM_BINS; bin += blockDim.x) {
histogram_s[bin] = 0;
}
__syncthreads();
// Vectorized accumulation (16 bytes per load)
constexpr int VEC_SIZE = sizeof(uint4);
unsigned char values[VEC_SIZE];
const int num_vecs = num_elements * sizeof(unsigned char) / VEC_SIZE;
const uint4* data_vec = reinterpret_cast<const uint4*>(data);
for (int i = idx; i < num_vecs; i += stride) {
*reinterpret_cast<uint4*>(values) = data_vec[i];
#pragma unroll
for (int j = 0; j < VEC_SIZE; ++j) {
atomicAdd(&histogram_s[values[j]], 1);
}
}
// Handle tail elements
const int tail_start = num_vecs * VEC_SIZE;
for (int i = tail_start + idx; i < num_elements; i += stride) {
atomicAdd(&histogram_s[data[i]], 1);
}
__syncthreads();
// Write block histogram to global
for (int bin = threadIdx.x; bin < NUM_BINS; bin += blockDim.x) {
int bin_value = histogram_s[bin];
if (bin_value > 0) {
atomicAdd(&histogram[bin], bin_value);
}
}
}
The #pragma unroll directive ensures the inner loop is fully unrolled at compile time since VEC_SIZE is known (16).
The tail handling is necessary when the input size isn’t a multiple of 16. For our benchmark with $2^{30}$ elements, the tail is empty, but production code must handle arbitrary sizes.
| Kernel | Time (ms) | Bandwidth | % Peak |
|---|---|---|---|
| Global Atomic | 276.13 | 3.89 GB/s | 0.1% |
| Shared Atomic | 1.53 | 703.10 GB/s | 21.0% |
| Shared Atomic (vectorized) | 0.47 | 2297.21 GB/s | 68.5% |
| CUB DeviceHistogram | 0.50 | 2139.35 GB/s | 63.8% |
Vectorized loads deliver more improvement. This brings performance to 68.5% of peak bandwidth, which is on par with CUB’s DeviceHistogram.
Note that we are still only achieving 68% of peak bandwidth, as atomic contention remains a limiting factor that cannot be fully eliminated. Even with shared memory privatization, frequently accessed bins still cause threads to serialize their updates, and shared memory atomics add nontrivial overhead. As a result, the kernel remains limited by contention rather than by memory bandwidth alone.
Further optimizations, such as warp-private histograms or warp-aggregated atomics, can reduce contention further at the cost of increased shared memory usage, which may limit occupancy.
Conclusion
These optimizations transformed histogram performance from 0.1% to 68.5% of peak bandwidth:
Privatization moves the histogram from global to shared memory, reducing atomic latency and limiting contention to within a block.
Vectorized loads with uint4 read 16 bytes per memory transaction instead of 1, better utilizing the memory system.
Histogram optimization is fundamentally about managing contention rather than eliminating it, and performance improves as the scope of conflicts is reduced from the grid level to the block level.