How Data Type Width Affects GPU Memory Throughput
Introduction
Efficient global memory access is fundamental for memory-bound GPU kernels.
In this post, I benchmark memcpy throughput using different data type widths, from 1 to 32 bytes, by running a templated CUDA kernel that reinterprets the source and destination buffers as wider vector types (uint8_t, uint16_t, uint32_t, uint64_t, uint4).
The benchmark code and plotting scripts are available in this repository.
Methodology
The kernel used for the study is shown below:
template <typename T, typename VecT>
__global__ void memcpy_kernel(
T* __restrict__ dst,
const T* __restrict__ src,
size_t n_elements)
{
size_t idx = blockIdx.x * blockDim.x + threadIdx.x;
size_t stride = blockDim.x * gridDim.x;
size_t total_bytes = n_elements * sizeof(T);
size_t n_vecs = total_bytes / sizeof(VecT);
// Vector-width copy
for (size_t i = idx; i < n_vecs; i += stride) {
reinterpret_cast<VecT*>(dst)[i] =
reinterpret_cast<const VecT*>(src)[i];
}
// Remainder copy
size_t start_elem = (n_vecs * sizeof(VecT)) / sizeof(T);
for (size_t i = start_elem + idx; i < n_elements; i += stride) {
dst[i] = src[i];
}
}
The evaluated instantiations are:
memcpy_kernel<int8_t, uint8_t> (...)
memcpy_kernel<int8_t, uint16_t> (...)
memcpy_kernel<int8_t, uint32_t> (...)
memcpy_kernel<int8_t, uint64_t> (...)
memcpy_kernel<int8_t, uint4> (...)
Results and Discussion
The figure below shows achieved bandwidth vs array size for different data widths on H100 (block size = 1024). Wider vector types consistently deliver higher throughput, with 16-byte loads approaching peak HBM bandwidth.
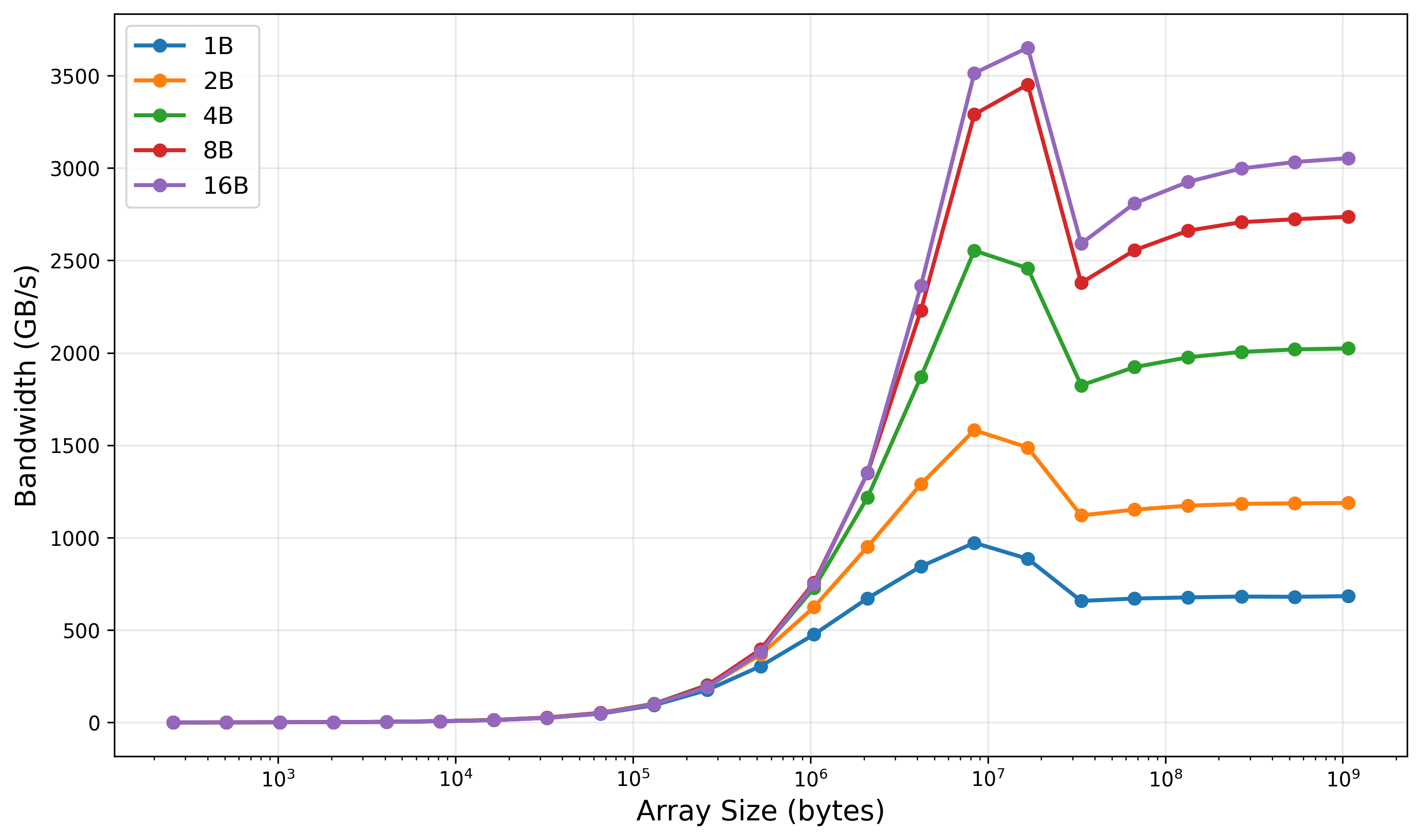
The figure can be divided into three regions:
-
Latency-dominated region (≤10⁵–10⁶ bytes)
All data type widths perform almost identically. Bandwidth is extremely low. Execution time is dominated by kernel launch overhead, instruction latency, and synchronization.
-
Cache-boosted peak region (≈10⁶–10⁷ bytes)
Throughput rises rapidly here. The widest types show a spike that can exceed theoretical HBM bandwidth. This happens because the working set fits partially or fully in L2 cache (H100 L2 = 50 MB). Therefore, these peaks are cache effects and do not reflect true device memory throughput.
-
HBM-dominated plateau region (≥10⁷–10⁸ bytes)
Once the working set exceeds L2, all curves settle into the true HBM bandwidth regime:
-
uint8_t: ~650–700 GB/s -
uint16_t: ~1150–1200 GB/s -
uint32_t: ~1950–2050 GB/s -
uint64_t: ~2550–2700 GB/s -
uint4(16B): ~3000–3100 GB/s
H100 HBM3 theoretical peak (SXM) is ~3.35 TB/s. The 16-byte vector load (
uint4) reaches ~90–93% of peak, which is typical for memcpy workloads.Narrower types require more instructions and more memory transactions per element, which reduces memory-level parallelism and prevents full HBM saturation.
-
Conclusion
Before using wider vector types, keep the following in mind:
-
Alignment is required. Device allocations are aligned, but any pointer offset must also respect the vector width. Misaligned vector loads cause faults or silent slowdowns.
-
Registers increase with vector width. Wider loads consume more registers per thread and can reduce occupancy or lead to register spilling.
With those constraints satisfied, wider data types offer clear benefits:
-
Higher memory bandwidth
-
Fewer instructions per byte moved
-
Lower overhead per transaction
-
Better ability to saturate HBM bandwidth
For memory-bound kernels, using 8-, or 16-byte, vector loads is often a simple and effective optimization.