Flash Attention From Scratch: 7 Kernels to 187 TFLOPS on A100
This post builds flash attention from raw CUDA and PTX, one optimization at a time. Each kernel introduces exactly one idea, benchmarked against the previous to isolate its impact. The final result reaches 92% of FlashAttention-2 on an A100. The benchmark code is available in this repository.
Config: FP16 I/O, FP32 accumulators, forward pass only, non-causal, $d{=}128$, batch${=}16$, heads${=}16$. All GEMMs use mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32.
The Algorithm
Standard attention computes $O = \text{softmax}(QK^\top / \sqrt{d})\, V$, materializing the full $N \times N$ score matrix. Flash attention avoids this by tiling over the KV sequence dimension. For each block of $B_r$ query rows, we iterate over blocks of $B_c$ key/value rows, accumulating $O$ in registers with online softmax correction.
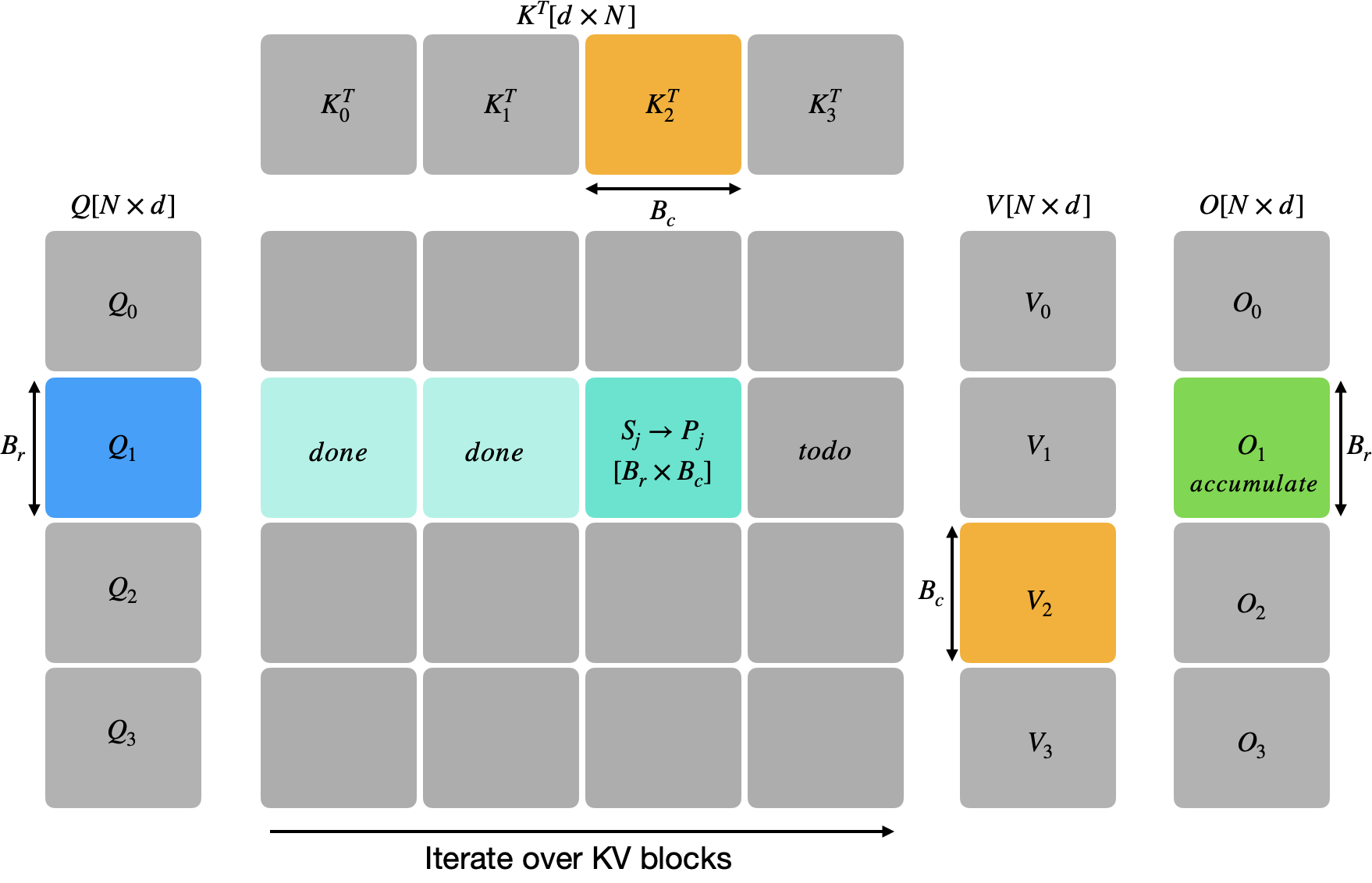
The correction factor $\alpha \leq 1$ rescales all previous accumulations whenever a new KV block introduces a larger row-max. On the first block $\alpha$ is zero (since $m = -\infty$), so the rescale is skipped. All intermediate state—$S$, $P$, $m$, $\ell$—lives in registers. Q, K, V tiles live in shared memory (though different optimizations may promote some to registers when the budget allows). $O$ accumulates in FP32 and is written to global memory once at the end.
Background
This section covers the FA-specific machinery. The MMA instruction, fragment register layouts, and ldmatrix are covered in the PTX HGEMM post. Fragment layout diagrams from the PTX ISA are the canonical reference.
The key facts for this post: each MMA computes a $16 \times 8$ output tile. Fragment A is $16 \times 16$ (4 uint32_t registers, row-major). Fragment B is $16 \times 8$ (2 registers, column-major). Fragment C/D is $16 \times 8$ (4 float registers, accumulator). ldmatrix.x4 loads a $16 \times 16$ tile from SMEM into A-fragment layout. ldmatrix.x2.trans loads $16 \times 8$ with per-$8 \times 8$ transpose into B-fragment layout.
Tiling Parameters
Each CTA processes $B_r$ query rows through two GEMMs: QK produces scores $S$ of size $B_r \times B_c$, and PV accumulates output $O$ of size $B_r \times d$. Rows are divided among warps, then subdivided into M-tiles of 16 rows (one MMA row group). The table below shows tiling for the QK GEMM; PV dimensions follow by swapping $B_c$ and $d$ (so PV_K_TILES $= B_c / 16$ and PV_N_TILES $= d / 8$).
| $B_r$ | $B_c$ | Warps | M_TILES | N_TILES | K_TILES | |
|---|---|---|---|---|---|---|
| Kernel 01 | 64 | 32 | 2 | 2 | 4 | 8 |
| Kernels 02–05 | 64 | 128 | 4 | 1 | 16 | 8 |
| Kernels 06–07 | 128 | 64 | 4 | 2 | 8 | 8 |
N_TILES $= B_c / 8$ is the number of $16 \times 8$ MMA output tiles across the score columns. K_TILES $= d / 16 = 8$ is the reduction dimension, constant for all kernels. M_TILES is the key variable—when M_TILES$=2$, each K/V fragment loaded once serves both M-tiles (the kernel 06 optimization).
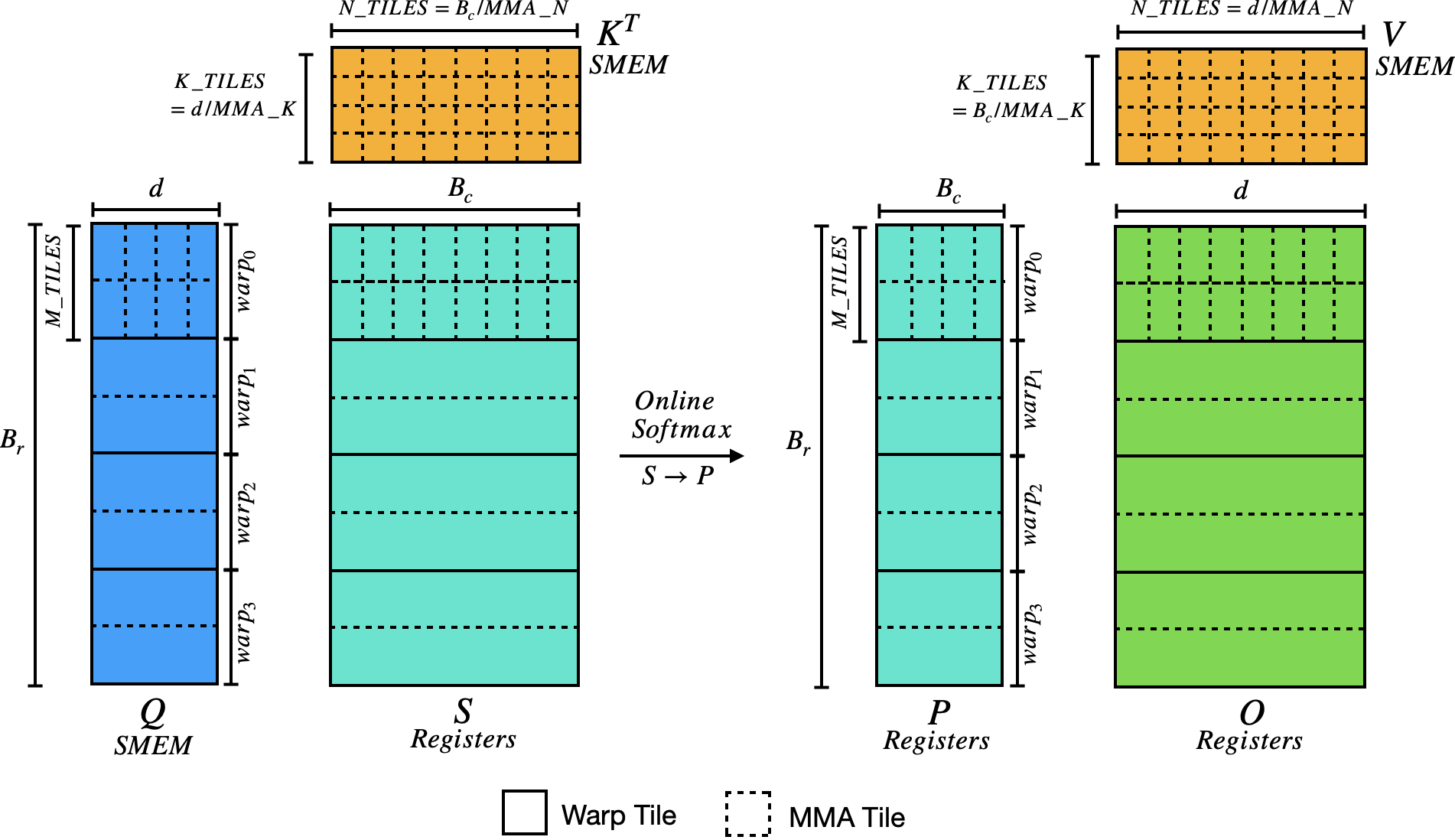
Online Softmax on MMA Fragments
Softmax is row-wise. From the FragmentC layout, each thread owns elements in exactly 2 rows of the $16 \times 8$ output (rows group_id and group_id + 8). Four threads share each row, each holding 2 consecutive columns. Row-wide max and sum need a cross-lane reduction—two __shfl_xor_sync calls (masks 1 and 2) reduce across all 4 lanes:
float row_max = fmaxf(S.reg[row*2], S.reg[row*2+1]);
row_max = fmaxf(row_max, __shfl_xor_sync(MASK, row_max, 1));
row_max = fmaxf(row_max, __shfl_xor_sync(MASK, row_max, 2));
P in Registers: FragmentC → FragmentA
After softmax, S (FP32 accumulators) becomes P and feeds directly into the PV GEMM as an A operand (FP16). The FragmentC and FragmentA register layouts are compatible—each thread’s elements map to the same matrix positions—so the conversion is just an in-register FP32→FP16 pack. No shared memory staging needed. All kernels use this approach. (Some optimizations might prefer SMEM staging to reduce register pressure—the recurring theme of flash attention optimization is the delicate balance between shared memory and registers.)
Kernel 01: Base (29.5 TFLOPS)
File: 01_base.cuh Tile: $B_r{=}64,\; B_c{=}32$ Warps: 2
The starting point. Q is loaded once into SMEM and stays resident for the entire mainloop. Each warp handles M_TILES$=2$ groups of 16 rows. K and V are loaded synchronously per KV block.
load Q -> SMEM; wait; sync
O = 0; m = -inf; l = 0
for j = 0 .. N/BC:
load K[j], V[j] -> SMEM; wait; sync
for mt = 0..M_TILES:
S = gemm_qk(smem_Q, smem_K, warp_row + mt*16)
S *= 1/sqrt(d)
online_softmax(S, O[mt], m, l)
O[mt] += gemm_pv(P_from_S, smem_V)
sync
epilogue: O /= l, convert FP16, store to GMEM
The QK GEMM loads Q via ldmatrix.x4 (one A fragment per k-tile) and K$^\top$ via ldmatrix.x4 + register reorder. The PV GEMM uses P-in-registers and loads V via ldmatrix.x2.trans.
Loading K$^\top$
K is stored row-major $[B_c \times d]$ in SMEM, but the QK GEMM needs $K^\top$ as B operands. We load a $16 \times 16$ block of K rows with ldmatrix.x4 and split the output registers into two B fragments:
ldmatrix.sync.aligned.m8n8.x4.shared.b16 {r0,r1,r2,r3}, [addr];
// r0 = K[n=0..7, k=0..7] r2 = K[n=0..7, k=8..15]
// r1 = K[n=8..15, k=0..7] r3 = K[n=8..15, k=8..15]
b0 = {r0, r2}; // B fragment for n=0..7
b1 = {r1, r3}; // B fragment for n=8..15
One ldmatrix.x4 replaces two ldmatrix.x2.trans calls, halving the K$^\top$ load count. The QK GEMM inner loop loads one K pair per k-step and fires two MMAs (one per B fragment).
The Bottleneck
At 29.5 TFLOPS, this kernel is crushed by shared memory bank conflicts. Every ldmatrix hits the same banks because rows are 128 elements (256 bytes $= 8$ bank cycles) with no offset variation. The small tile ($B_c{=}32$) also gives low arithmetic intensity.
Kernel 02: Swizzle (165 TFLOPS)
File: 02_swizzle.cuh Tile: $B_r{=}64,\; B_c{=}128$ Warps: 4
The single biggest jump: +459%. Two changes, inseparable in practice.
XOR Swizzle
When ldmatrix.x4 loads 8 rows at stride 128 (256 bytes = 8 bank cycles), every row maps to the same banks—8-way conflict. The fix XOR-permutes the column group index with the row:
template<int STRIDE>
int swizzle_offset(int row, int col) {
return row * STRIDE
+ (((col >> 3) ^ (row & 7)) << 3) + (col & 7);
}
Row $r$ accesses column group $g \oplus (r \bmod 8)$, spreading 8 consecutive rows across all 32 banks. XOR is self-inverse ($x \oplus y \oplus y = x$), so the same formula works for writes and reads. Every access path—tile loader, ldmatrix, P scatter, epilogue—uses swizzle_offset.
Larger Tile
$B_c$ grows from 32 to 128. More work per CTA, fewer mainloop iterations, better amortization of softmax overhead. Without swizzle, $64 \times 128$ would be even more conflict-bound.
Kernel 03: KV Pipelining (175 TFLOPS)
File: 03_kvpipe.cuh Tile: $64 \times 128$ Warps: 4
Overlaps GMEM loads with compute using cp.async. In kernel 02 the tensor cores idle while K/V load from global memory. cp.async.cg copies 16 bytes from GMEM to SMEM without touching registers, and commit_group/wait_group let us fence and wait on in-flight copies. K[0] is issued before the loop:

K and V have separate SMEM buffers, so loading one while reading the other is safe. V loads hide behind the QK GEMM. K[j+1] loads hide behind the PV GEMM.
This kernel also hoists P fragment conversion (FP32→FP16) out of the PV GEMM inner loop, converting all P fragments between softmax and PV. Separating conversion from the inner loop gives the compiler more room to schedule ldmatrix and mma instructions.
Kernel 04: V Pair Loading (176 TFLOPS)
File: 04_vpair.cuh Tile: $64 \times 128$ Warps: 4
Uses ldmatrix.x4.trans to load two V fragments per call. V is stored row-major $[B_c \times d]$. The PV GEMM needs it as B operands (column-major). A single ldmatrix.x2.trans loads one $16 \times 8$ B fragment, but ldmatrix.x4.trans loads a full $16 \times 16$ with per-$8 \times 8$ transpose, producing two B fragments from one instruction. The .trans modifier changes how sub-tiles map to registers—fragments group contiguously instead of interleaving:
ldmatrix.sync.aligned.m8n8.x4.trans.shared.b16 {r0,r1,r2,r3}, [addr];
b0 = {r0, r1}; // B fragment for d=0..7 (contiguous)
b1 = {r2, r3}; // B fragment for d=8..15 (contiguous)
// Compare K^T: b0 = {r0, r2}, b1 = {r1, r3} (interleaved)
The PV GEMM inner loop now steps N-tiles by 2:
for k in 0..PV_K_TILES:
for n in 0..PV_N_TILES step 2:
v0, v1 = load_vt_pair(smem_V, k, n) // 1 ldmatrix.x4.trans
mma(O[n], P[k], v0)
mma(O[n+1], P[k], v1)
+0.3%. Modest because V loads were already somewhat latency-hidden, but it reduces LSU pressure.
Kernel 05: exp2f Fusion (181 TFLOPS)
File: 05_exp2f.cuh Tile: $64 \times 128$ Warps: 4
Fuses the softmax scale into exp2f to cut instruction count. The standard path takes 4 instructions per element: FMUL to scale S by $1/\sqrt{d}$ (separate pass), FADD to subtract $m$, FMUL by $\log_2 e$ (inside __expf), and MUFU.EX2. Switching to $\log_2$ space:
where SCALE_LOG2 $= \log_2 e / \sqrt{d}$ and $m’$ is stored in $\log_2$ space. The multiply-subtract fuses into one FFMA, followed by one MUFU.EX2: 2 instructions instead of 4, shorter dependency chain.
Standard (expf) |
Fused (exp2f) |
|
|---|---|---|
| Scale pass | S *= 1/sqrt(d) (separate loop) |
eliminated |
| Row max | $m = \max(S)$ | $m’ = \max(S) \cdot \text{SCALE_LOG2}$ |
| Exponent | expf(S*scale - m): 4 ops |
exp2f(S*SL2 - m'): 2 ops |
| Correction | $e^{m_\text{old} - m_\text{new}}$ | $2^{m_{\text{old}}^{\prime} - m_{\text{new}}^{\prime}}$ |
The separate S *= softmax_scale loop before softmax is eliminated entirely.
Kernel 06: Batched M-Tiles (187 TFLOPS)
File: 06_batched.cuh Tile: $B_r{=}128,\; B_c{=}64$ Warps: 4
Batches multiple M-tiles per K-tile iteration, reusing each K/V fragment across all M-tiles. The tile shifts from $64 \times 128$ to $128 \times 64$: more Q-rows means more reuse, fewer KV columns means V fits in registers.
With 128 Q-rows and 4 warps, each warp handles 32 rows = M_TILES$=2$. In the non-batched kernels, each M-tile loads K fragments independently. The batched variant loads each K pair once and feeds it to both:
for k in 0..K_TILES:
Q_frag[0] = load_a(smem_Q, row_0, k*16)
Q_frag[1] = load_a(smem_Q, row_1, k*16)
for each K pair (np):
K0, K1 = load_kt_pair(smem_K, np, k) // loaded ONCE
mma(S[0][2*np], Q[0], K0) // M-tile 0
mma(S[0][2*np+1], Q[0], K1)
mma(S[1][2*np], Q[1], K0) // M-tile 1 reuses K
mma(S[1][2*np+1], Q[1], K1)
V Fully Preloaded into Registers
Before the PV GEMM, all V fragments are loaded into a register array via ldmatrix.x4.trans. With $B_c{=}64$: PV_K_TILES $\times$ PV_N_TILES $= 4 \times 16 = 64$ FragmentB $= 128$ registers. The PV GEMM is then purely register-to-register—zero LSU contention during compute.
Why $128 \times 64$ Instead of $64 \times 128$?
More Q-rows means more M-tiles for batching—each K/V fragment loaded once serves $2\times$ the compute. And $B_c{=}64$ keeps V_frags within the register budget; at $B_c{=}128$, V would need 256 registers.
Kernel 07: Double-Buffered GEMM (186.5 TFLOPS)
File: 07_dbuf.cuh Tile: $128 \times 64$ Warps: 4
Ping-pong double-buffers fragment loads inside the GEMM inner loops. ldmatrix has ~30-cycle latency. Issue the load for the next fragment pair before computing with the current one:
FragmentB K_pp[2][2]; // ping-pong slots
load K_pp[0] // prologue
for each (k, np):
load K_pp[nxt] from SMEM // prefetch next
for mt in 0..M_TILES:
mma(S[mt][..], Q[mt], K_pp[cur][0])
mma(S[mt][..], Q[mt], K_pp[cur][1])
Unlike kernel 06, V is not preloaded—loads are interleaved with compute via double-buffering.
Result: −0.5% regression. With M_TILES$=2$, each K/V pair gets 4 MMAs (~64 cycles) of compute between loads—well above the ~30-cycle ldmatrix latency. Double-buffering adds register pressure without hiding meaningful latency. This confirms that batched reuse (kernel 06) already saturates the compute-to-load ratio—prefetching adds pressure without payoff.
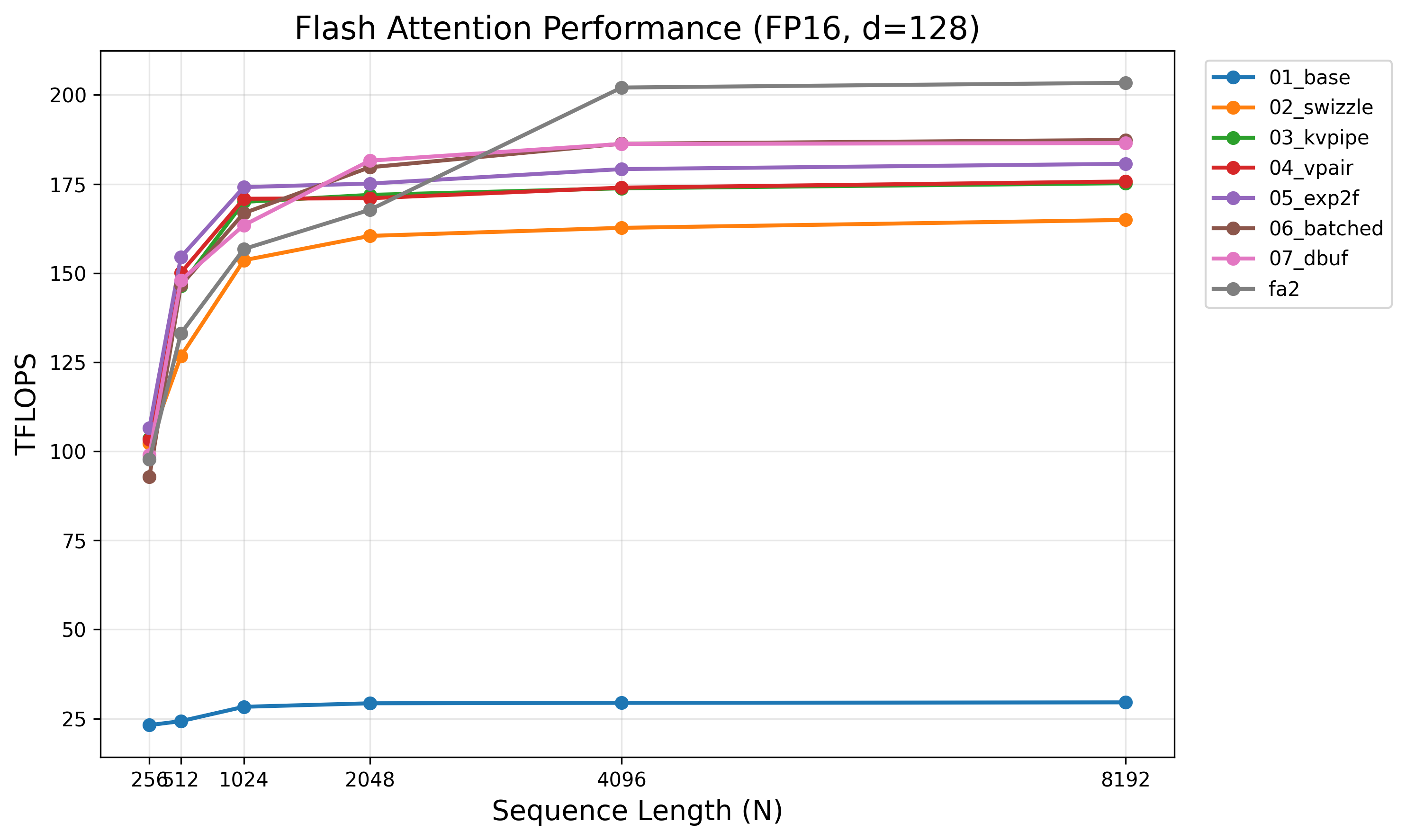
Performance Summary
| Kernel | Key Optimization | Tile | TFLOPS | vs Prev |
|---|---|---|---|---|
| 01_base | Naive tiled flash attention | 64×32 | 29.5 | — |
| 02_swizzle | XOR swizzle + larger tiles | 64×128 | 165.0 | +459% |
| 03_kvpipe | cp.async KV pipelining | 64×128 | 175.1 | +6.1% |
| 04_vpair | ldmatrix.x4.trans V pairs | 64×128 | 175.7 | +0.3% |
| 05_exp2f | Fused exp2f softmax | 64×128 | 181.1 | +3.1% |
| 06_batched | Batched M-tiles + V in regs | 128×64 | 187.3 | +3.4% |
| 07_dbuf | Double-buffered GEMM | 128×64 | 186.4 | −0.5% |
| FlashAttention-2 | 203.7 |
Best: 187.3 TFLOPS (kernel 06) = 92% of FA2.
All numbers at $N{=}8192$, batch${=}16$, heads${=}16$, $d{=}128$, A100-SXM4-80GB.
The Remaining Gap
The remaining 8% is instruction-level. Sonny Li’s Flash Attention from Scratch series demonstrates one path to closing it: 16 kernels of increasingly aggressive instruction reduction and layout tuning, reaching 99.2% of FA2 on A100. FA2 uses CuTe’s compile-time layout algebra, which encodes tiling, swizzling, and memory access patterns as types, giving the compiler substantially more scheduling freedom than hand-rolled index arithmetic.
92% is a reasonable stopping point for a from-scratch implementation. The kernels here isolate what the algorithmic and memory-system optimizations buy you; the last 8% is instruction-level craft.